Last
revision: June 27, 2004 (c) Georg Lind
Evaluation
von Bildung -
Eine systematische Einführung in die
entwicklungsorientierte
Evaluation
Georg
Lind
(im Aufbau;
bitte mit Revisions-Datum zitieren)
| Evaluation
kann wichtig und nützlich sein --
aber auch gefährlich,
wenn
sie nicht selbst evaluiert und kritisch hinterfragt wird. |
Zusammenfassung
Einführung
Evaluation
gilt heute immer mehr als der Königsweg zur Verbesserung unseres Bildungssystems.
So erhofft sich die Kultusministerkonferenz durch die Einführung einer systematischen
Evaluation auf der Grundlage von sogenannten "Bildungsstandards" eine
starke Verbesserung unserer Schulen:
"Hinzu
kommt, dass die Ergebnisse der skandinavischen Staaten und einiger angloamerikanischer
Staaten die (allerdings empirisch bisher nicht belegte) Vermutung stützen,
dass Staaten, in denen eine systematische Rechenschaftslegung über die Ergebnisse
erfolgt - sei es durch regelmäßige Schulleistungsstudien, durch zentrale
Prüfungen oder durch ein dichtes Netz von Schulevaluationen -, insgesamt
höhere Leistungen erreichen." (KMK, 2003, S. 9)
Dem
halten Kritiker entgegen, dass dieser erhoffte Effekt nur ein eintreten kann,
wenn Evaluation, Bildungsstandards und Tests sehr hohen Anforderungen genügen
(Lewis, 2001). Bemerkenswerter Weise verlässt sich die KMK hier auf bloße
Vermutung, statt auf empirische Studien. Solche sind durchgeführt worden
und deuten eher auf das Gegenteil hin (Amrein & Berliner, 2002).
Folgende
Probleme scheinen für negative Effekte von Evaluationsprozessen hauptsächlich
verantwortlich zu sein:
- Sanktionen:
Die Verbindung der Evaluationsergebnisse mit hohen Sanktionen oder Gratifikationen.
- Personen-Fokus:
Der Fokus der Evaluation auf Personen oder Personengruppen und individuellen Institutionen
wie Schulen, statt auf bestimmten Maßnahmen und Methoden.
- Design-Fehler:
Der Verzicht auf minimale wissenschaftliche Standards bei der Untersuchungsanlage
(Design), um eine eindeutige Zuschreibung der Ergebnisse zu gewährleisten.
- Validitätsmängel:
Mängel in der Validität der eingesetzten Tests in Bezug auf konkrete
Bildungsstandards, auf übergreifende Bildungsziele, auf Kompetenzen, die
über die ganze Lebensspanne benötigt werden, und auf neue psychologische
Erkenntnisse über die Natur und die Entwicklung von Lernprozessen.
In
diesem Papier wird ein alternativer Evaluationsansatz vorgestellt, der sich in
allen vier Punkten von den in der Öffentlichkeit diskutierten Ansätzen
unterscheidet und der geeignet erscheint, das Bildungssystem zu verbessern.
Literatur
Amrein
& Berliner (2002). High Stakes testing, uncertainty, and student learning.
Education Policy Analysis Archives, 10(18). Bezogen von http://epaa.asu.edu/epaa/v10n18/.
KMK
- Kultusministerkonferenz (2003). Entwicklung und Implementation von Bildungsstandards.
Bonn: KMK-Sekretariat.
Lewis,
A. (2001). Benchmakrs for accountability. Are were there yet? Proceedings of
the CRESST conference. Los Angelos, CA: National Center for Research on Evaluation,
Standards and Student Testing -- CRESST.
Überblick
- Entwicklungsorientierte
Evaluation von Bildungsinstitutionen und Lehrmethoden
meint die
Bewertung von Methoden und Institutionsformen, also der Überprüfung
der Effekte und der Effektivität von bestimmten Bildungsinstitutionen oder
von didaktischen und pädagogischen Methoden der Stoffvermittlung und Fähigkeitsförderung
gemäß allseits akzeptierter Lernziele.
Diese ist klar zu unterscheiden
von den Zielen und Methoden der sogenannten "sanktionsbewehrten Evaluationen"
(high-stake testing) oder externen Evaluationen von Personen (z.B. von Schulkollegien,
Lehrern oder Lernenden), die dem Ziel dienen, Personen oder Gruppen nach äußeren
Vorgaben zu bewerten und sie gemäß dieser Bewertung zu belohnen oder
zu bestrafen.
-
Das Minimaldesign für eine entwicklungsorientierte Evaluation
besteht aus:
- Vortests
mit den Lernenden
- Erster
Nachtest mit den Lernenden zur Bestimmung unmittelbarer Effekte
- Zweiter
Nachtest mit den Lernenden -- im Abstand von mindestens einigen Wochen, besser
noch einigen Monaten oder Jahren -- zur Bestimmung dauerhafter oder nachhaltiger
Effekte.
- Vor- und Nachtests
bei einer -- hinsichtlich aller relevanten Variablen vergleichbaren -- "Kontrollgruppe"
oder, sofern dies aus praktischen Gründen nicht möglich ist, Vergleich
mit den Ergebnissen aus repräsentativen Base-line-Studien.
- Optional: Verbleibstudien und Langzeitnachuntersuchungen.
Merke: Eine Einmalstudie
ohne Vortest und ohne Querschnittvergleiche ist auch in jedem anderen Sinne keine
wissenschaftlich fundierte Evaluation. Aus ihr können keinerlei Rückschlüsse
über die Wirksamkeit bestimmter bildungspolitischer Maßnahmen oder
pädagogisch-didaktischer Methoden gezogen werden.
-
Die Beobachtungs- und Messinstrumente
für eine
solche Evaluation können aus folgenden Versatzteilen zusammengestellt werden
(unerlässliche, aber bislang oft vernachlässigte Teile sind fett
gedruckt):
- Persönliche
Angaben, subjektive Lernziele und Erwartungen der Lernenden an das Lernergebnis
in der zu evaluierenden Lerneinheit
- Vorbildung
und Vorerfahrungen der Lernenden; Lernstile
- Fachliche und überfachliche
Kenntnisse und Fähigkeiten
- Subjektive
Evaluation des Fähigkeitszuwachses der Lernenden (Beispiel)
- Subjektive Lehrevaluation
durch die Lernenden
- Beobachtungen
der Lehrenden selbst (auch videounterstützt)
- Beobachtungen
von Peers, externen Experten für das Lehr- oder Unterrichtsfach und Experten
für Lehren und Lernen (Allg. Didaktik, Lernpsychologie, Fachdidaktik)
- Beispiel
für einen Vortest (Pädagogische Psychologie, Moralische Urteilsfähigkeit)
- Beispiel
für einen Nachtest (Pädagogische Psychologie, Moralische Urteilsfähigkeit)
- Die Instrumentteile
3.1 bis 3.3 finden Einsatz im Vortest,
die Teile 3.3 bis 3.7 im Nachtest.
- Alle Instrumente
müssen vorerprobt sein. An die Vorerprobung von Instrumenten zur Erfassung
von Fachkenntnissen und -fähigkeiten sind hohe Anforderungen zu stellen.
Die Auswahl der Instrumente sollte auf der Grundlage einer klaren Zieldefinition
(was soll in dieser Institution bzw. diesem Kurs erreicht werden?) und von Forschungsergebnissen
geschehen.
- Merke:
Evaluationsinstrumente, in denen nicht nach dem Lernzuwachs gefragt wird und keine
Messung von Lernzuwachs erfolgt, sind für den Einsatz in Bildungsinstitutionen
kaum geeignet.
-
Evaluationsbericht
- Der
Bericht muss alle Angaben enthalten, die für eine vollständige Replikation
der Evaluation notwendig sind (inklusive Auswertung)
- Der
Bericht muss in so verfasst sein, dass andere Personen (einschließlich der
Lernenden) ihn verstehen, kritisch kommentieren und Schlussfolgerungen für
die eigene Lehre ziehen können.
- Bei
Effekten soll immer die Effektstärke
und, wenn möglich, das Ausmaß an absoluten Veränderungen
angegeben werden. Die Angabe von statistischen "Signifikanzen" ist unzureichend
und heute nicht mehr akzeptabel.
- Merke:
Berichte, in denen Angaben zur Effektstärke und Rohwerte (absolute und/oder
relative Antwort- und Lösungshäufigkeiten) fehlen, und deren zentralen
Kennwerte nicht so erklärt sind, dass sie von Laien mit erfolgreicher Absolvierung
der Pflichtschule verstanden werden können, sind sehr Frag-würdige
Grundlagen für bildungspolitische Entscheidungen.
- Jede
Evaluation muss selbst nach strengen Maßstäben evaluiert werden.
- Das Untersuchungsdesign
muss so gewählt werden, dass eine möglichst eindeutige Beantwortung
der Evaluationsfrage möglich ist. Das heißt vor allem, dass eine möglichst
eindeutige Zuordnungen der zentralen Effekte zu Kausalfaktoren (z.B. Lehrmethode,
Stoff, Schulorganisation) gesichert ist (Designvalidität); und
- dass die eingesetzten
Messinstrumente genau das messen, was sie zu messen vorgeben (Instrument-Validität).
- Diese Kriterien
für eine gute Methodenevaluation können nicht unverändert auf die
Evaluation von Personen oder Institutionen (z.B. Schulen) übertragen werden.
- Merke:
Eine Evaluation, die ihren eigenen strengen Maßstäben nicht genügen
will oder kann, ist nicht mit dem Gleichheitsgebot einer demokratisch erfaßten
Gesellschaft zu vereinbaren.
- Merke:
Eine schlechte Evaluation ist schlimmer als gar keine!
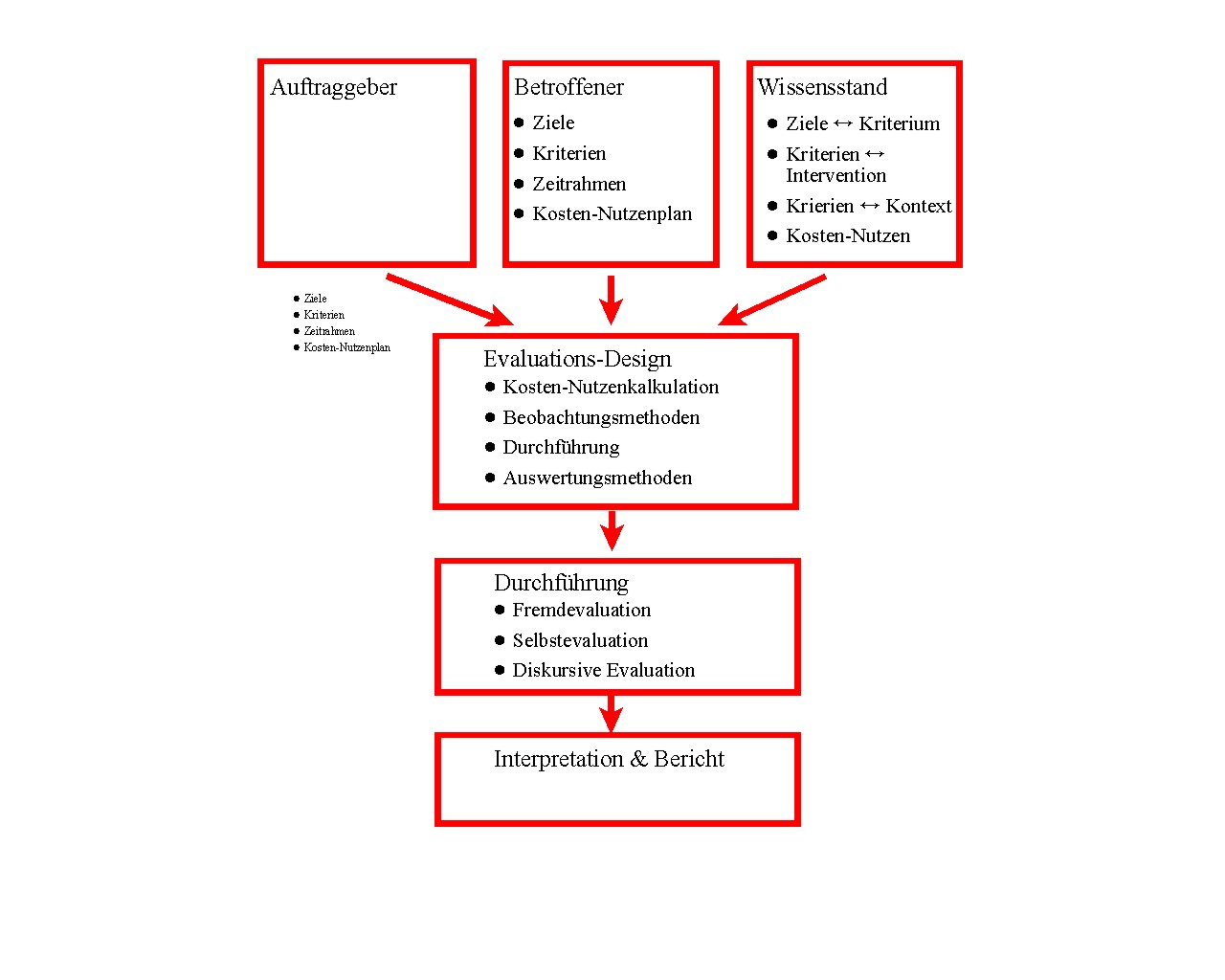
Wichtige
im Prozess der DEE beteiligten Personen, Institutionen und Tätigkeiten sind
im folgenden Schaubild skizziert. In diesem Skript werden einige davon näher
betrachtet. Es werden darüber hinaus Definitionen gegeben und Hinweise für
konkrete Anwendungen.
1.
Begriffe
1.1
Beobachtung
Beobachtung
steht hier als Oberbegriff für
alle Formen der Datengewinnung, also auch für Befragungen, Interviews, Dokumentenanalysen
etc.).
Wissenschaftliche
Beobachtung meint die systematische, kontrollierte und objektiv nachvollziehbare
Aufzeichnung von bestimmten Geschehnissen, um Daten zu gewinnen, mit denen man
Evaluations-Hypothesen überprüfen kann.
Beispiel:
Mit einer Beobachtung soll überprüft werden, ob die Lehrmethode X zu
mehr Aufmerksamkeit der Studierenden führt. Daher muss genau definiert werden,
was mit Aufmerksamkeit gemeint ist, und die Beobachtung so angelegt sein, dass
genau dieses beobachtet wird.
�
Systematisch meint, dass jede Beobachtung immer in
ein System von Zwecken und Annahmen eingebettet ist, und dieses System explizit
zu machen ist, damit die Ergebnisse der Beobachtung auf ihre Validität für
eine Evaluation hin überprüft werden können.
Beispiel:
Zweck der Beobachtung bzw. Evaluation ist die Durchführung eines Trainingsprogramms
für Dozenten, durch das diese die Aufmerksamkeit der Studierenden verbessern
sollen. Annahme ist, dass die Aufmerksamkeit wesentlich (oder gar ausschließlich)
durch das Verhalten des Dozenten beeinflussbar ist und nicht bloß durch
den Stoff, die Einstellung der Studierenden und andere Variable. Sollten Zweifel
bestehen, dass diese Annahme zutrifft, sollten evtl. die anderen Faktoren auch
beobachtet oder "kontrolliert" werden.
Kontrolliert
meint, dass jede Beobachtung in einen bestimmten Kontext eingebettet ist, der
die Beobachtungen ebenso mitbestimmt wie der beobachtete Gegenstand selbst. Daher
muss auch der Kontext der Beobachtung in die Durchführung und Interpretation
der Beobachtung mit einbezogen und gegebenenfalls "kontrolliert" werden,
indem der Kontext weitgehend ausgeblendet, standardisiert oder systematisch variiert
wird.
Beispiel: Es gibt
Grund zu der Annahme, dass die Aufmerksamkeit der Studierenden auch durch den
Stoff (genauer: durch den Grad der Praxisrelevanz oder Konkretheit) bestimmt ist.
Also sollte auch dies beobachtet werden.

1.2
Evaluation
Wissenschaftliche
Evaluation bedeutet die Bewertung eines Zustands oder einer Entwicklung anhand
von wissenschaftlichen Beobachtungen auf der Basis von klar bestimmten Kriterien
für bestimmte Zwecke oder Ziele.
Kriterien beziehen sich auf einen zu erreichenden Zustand (Qualität, Leistung
o.a.), der durch bestimmte pädagogische Maßnahmen, Methoden oder Inhalte
erreicht werden soll, und der konkret und präzise beschrieben und beobachtet
bzw. gemessen werden kann. Kriterien werden oft aus Zwecken abgeleitet. Sie sind
selten ein Selbstzweck.
Beispiel:
Ein Kriterium könnte das Erreichen einer bestimmten Aufmerksamkeitsrate in
einer Klasse sein (90% statt, wie bisher, 30%). Dieses Kriterium soll Einhaltung
der Wartezeitregel durch den Lehrer erreicht werden.
Zwecke
beziehen sich auf längerfristige, weit gesteckte, oft eher allgemein formulierte
Ziele, die durch bestimmte pädagogische Maßnahmen, Methoden oder Inhalte
und durch die Evaluation erreicht werden sollen.
Beispiel:
Das Ziel ist einer neuen Unterrichtsmethode ist es, die Aufmerksamkeit der
Schüler zu steigern. Dies dient dem Zweck, eine bessere Lernmotivation und
ein größeres Lernpensum zu erreichen. Auch dieses dient wiederum einem
übergeordneten Zweck, nämlich die Fähigkeiten und Kenntnisse der
Jugendlichen auszuweiten und sie dadurch besser auf die Lösung verschiedenster
Aufgaben vorzubereiten, auf die sie -- vermutlich -- im Leben einmal stoßen
werden.
Mehr
zur ethymologischen Bedeutung von Evaluation (fremde Seite von Manfred Karbach).
2.
Evaluationzwecke
Der Zweck
einer Evaluation ist der allgemeine, übergeordnete Verwendungszusammenhang,
für den die Evaluation dient.
Im
folgenden werden einige Unterscheidungen getroffen, die für die Diskussion
von Zwecken relevant sind, wie z.B. die Unterscheidung nach Fremd- und Eigenzwecken.
Keine Evaluation entspricht einer drei hier vorgestellten Formen zu 100%, aber
viele lassen sich doch sowohl ihrem Selbstverständnis nach als auch ihren
Anlage nach gut zuordnen. So grenzt sich die PISA-Studie selbst eindeutig von
der internen Evaluation ab. Bei manchen Evaluationsstudien muss man genauer hinsehen,
um zu entscheiden, um welche Evaluationszwecke es sich handelt. So können
bei der internen Evaluation Fragebögen herangezogen werden, die von anderen
konstruiert wurden, ohne dass hierdurch die strenge Selbstbestimmung über
den Zweck und die Verwendung der Evaluation aufgegeben wird. Oder es können
bei einer externen Evaluation auch die Betroffenen angehört werden, ohne
dann ihnen eine nennenswerte Mitbestimmung eingeräumt wird.
2.1 Fremdzwecke (externe Evaluation)
-
Der Antrieb für die Evaluation kommt von außen
- Die Zwecke dienen
vorwiegend äußeren Personen und Institutionen, bleiben darüber
hinaus aber weitgehend unbestimmt
- Die Kriterien werden von außen festgelegt
- Die Wahl der Beobachtungs- und Auswertungsmethode wird von außen bestimmt
- Bei der Interpretation der Befunde werden die Betroffenen nicht angehört
und erhalten auch kein Einspruchsrecht
Beispiel:
Ein bekanntes Beispiel hierfür ist die PISA-Studie,
deren Autoren weder Lehrer noch Schüler an der Definition der Evaluationsziele
beteiligen und auch zu den vorliegenden Lehrplänen als normative Rahmen auf
Distanz gehen, wie nachfolgende Zitate zeigen:
- "Verzicht auf
transnationale curriculare Validität" (Baumert
et al., 2001, PISA-2000, S. 19)
- Curriculare Validität "tritt
in den Hintergrund" (S. 19)
- Es war "... nicht beabsichtigt wird,
den Horizont moderner Allgemeinbildung zu vermessen." (S. 21)
Statt dessen:
- Gewählt wurde ein eigenes "normatives ... didaktisches und bildungstheoretisches
Konzept" (S. 19),
- d.h. ein "normativer Ansatz ..., der sich nicht
durch spezifische Lehrplanvorgaben der Teilnehmerstaaten einengen ließ"
(S. 43).
- Über die "Klassen von Verwendungs- und Lebenssituationen"
der Aufgaben zum Leseverständnis wurde "pragmatisch entschieden"
(S. 19)
2.2
Eigenzwecke (interne Evaluation)
-
Der Antrieb zur Evaluation kommt von innen
- Die Zwecke dienen vor allem der
eigenen Entwicklung von Personen und Institutionen
- Die Kriterien werden
selbst festgelegt
- Die Wahl der Beobachtungs- und Auswertungsmethoden erfolgt
von den Betroffenen selbst
- Die Interpretation der Befunde und Validierung
der Werturteile erfolgt unter Beteiligung der evaluierten Personen.
Beispiel: Interne Evaluation im Rahmen eines schulischen Qualitätsmanagement:
"Es
geht um die Frage nach Standards und um Stärken und Schwachstellen. Das setzt
voraus, dass über Daten geredet wird, und die Daten in einem Kollegium, in
einer Forschergruppe, in der Schulleitung oder zwischen Schule und eventuell der
Schulaufsicht abgeglichen werden. Das schafft die Basis für die Begründung
von Werturteilen. Daten müssen ... kommunikativ, d.h. durch Abklärungsgespräche
validiert werden, und auf dieser Grundlage entsteht die Evidenz von Bewertungsurteilen
... Evaluation muss von Anfang an Thema der Schulentwicklung sein." (H.-G.
Rolff, 2001: Schulentwicklung konkret: Steuergruppe, Bestandsaufnahme, Evaluation.
Seeltze: Kallmeyersche Verlangsbuchhandlung, S. 83)
2.3 Gemeinsame Zwecke (entwicklungsorientierte
Evaluation)
-
System- oder Entwicklungsperspektive:
(a) Der Evaluierte legt Wert auf
hohe Transparenz und Anerkennung der eigenen Leistungen und Leistungsfähigkeit
durch externe Instanzen bzw. durch die Öffentlichkeit.
UND
(b) Der
Evaluierer legt beim Evaluierten Wert auf eine stetige Qualitätsentwicklung,
die mit Materialien und personellen Resourcen schonend umgeht, um systemische
Synergie-Effekte zu erzeugen bzw. Allgemeinkosten (Energie-Gewinnung, Arbeitslosenunterhalt
etc.) zu minimieren.
Gegenteil: Macht- oder Selektions-Perspektive.
-
Der Evaluations-Anlass kann von außen oder von innen kommen:
Beispiele:
(a) von außen: Die Studierenden sind nicht gut genug auf die Berufswelt
vorbereitet.
(b) von innen: Die Studierenden zeigen sich unzufrieden mit der
Integration von Theorie und Praxis im Studium.
-
Demokratische Gemeinschaft:
Planung,
Durchführung und Auswertung/Interpretation der Evaluation werden gemeinsam,
in gemischten Kommissionen (am "runden Tisch") besprochen und "validiert".
Beispiel: Kommunikative Validierung der Beurteilung einer Lehrerleistung:
"Notwendiges
Medium für die kommunikative Validierung <einer wertenden Beurteilung>
stellt das Gespräch dar: dabei geht es um Gespräche auf drei Ebenen:
Zwischen verschiedenen Beurteilern, zwischen Beurteiler und Beurteiltem und zwischen
dem Beurteiler und dritten Personen, die etwas zur Urteilsfindung beitragen können."
(H. Frommer & G. Bovet, 1999: Praxis Lehrerberatung -- Lehrerbeurteilung.
Hohehgehren: Schneider Verlag, S. 81)
2.4
Beispiel: Zweck des Bildungssystems / Lehrpläne etc
Die
Zwecke von Bildungsinstitutionen werden in Schulgesetzen und in allgemeinen Bildungstheorie
bzw. im Lehrplan (Curriculum) und Lehrbüchern festgelegt. Diese werden in
einer demokratischen Gesellschaft -- im Idealfall -- unter Mitwirkung von vielen
Beteiligten (von Eltern, Lehrer, Schulverwaltung, Bildungstheoretiker, Erziehungswissenschaftler,
Publizisten, Parlamentarier und -- ein bißchen jedenfalls -- von Schülern)
festgelegt und ausformuliert.
In
der Realität bestimmt -- zumeist nach einem Anhörungsprozess -- eine
kleine Gruppe von Parlamentariern und Regierungsmitgliedern, was in den Schulgesetzen
steht, und eine ebenfalls kleine Gruppe von Schulexperten (vor allem Lehrer),
die von der Kultusverwaltung dazu bestimmt worden sind, was in den Lehrplänen
steht.
In den letzten
Jahren ist zu beobachten, dass bei uns in Deutschland diese Gruppen heute größer
als früher sind und dass mehr Außenstehende (Wissenschaftler, Elternvertreter,
Lehrerverbände, Kirchen, Gewerkschaften etc.) in den Willensbildungsprozess
einbezogen werden und die Öffentlichkeit mehr Anteil an der Festlegung von
Zwecken und Zielen unseres Bildungssystems nehmen. Zudem zeigt sich ein Trend
zu weniger Festlegung in Einzelfragen und mehr Spielraum für Entscheidungen
vor Ort, in den Schulen und in den Klassenzimmern. Dadurch gewinnen der einzelne
Lehrer und die Schüler und Eltern mehr Einfluss auf die Ausgestaltung von
Zweck- und Zielsetzungen.
| | Quelle |
| Zwecke | Schulgesetzen,
Hochschulgesetzen etc., Bildungspläne |
| Ziele | Lehrpläne
(Curricular) |
Schulgesetze,
Bildungspläne und Lehrpläne legen also fest, was die Schule leisten
soll. An diesen Zwecken und Zielen muss sie sich messen lassen. An diesen Zwecken
und Zielen muss unser Bildungssystem auch gemessen werden, wenn man sich fragt,
was es leistet. Man nennt diese Anforderung an das Evaluationsdesign -- soweit
es die Ziele betrifft -- "curriculare Validität".
Aber
auch mit den Zwecken muss eine Evaluation in Übereinstimmung gebracht werden,
wenn sie funktional sein will, d.h., wenn sie zur Verbesserung des Bildungssystems
in dem dort festgelegten Sinne beitragen will. Dieser Anspruch ist in der Regel
sehr viel schwerer einzulösen als die curriculare Validität; oft lässt
er sich nur dadurch einlösen, dass man in unter Verweis auf vorliegende Forschungsbefunde
plausibel macht und ansonsten angibt, was an diesem Anspruch reine Theorie und
noch zu bestätigen ist.
Übungsfragen:
a)
Wer hat das Recht, Zwecke und Ziele von Bildung zu definieren? Ist die bisherige
Praxis (Schulgesetze, Lehrpläne) Ihrer Meinung nach legitim und richtig,
oder sollte sie geändert werden?
b) Welche Personen und Instanzen haben
bei der Festlegung dieser Zwecke und Ziele zu viel und welche zu wenig Gewicht?
c)Sollte die Definition von Zwecken und Zielen von Bildung (und damit die Kriterien
für eine Evaluation) statt dessen -- wie in der PISA-Studie -- von Experten
statt von Parlamenten und Kultusbehörden festgelegt werden? Wie sollen diese
Experten ausgewählt werden?
3.
Personen- oder Methodenevaluation?
3.1
Personen- und Institutionen-Evaluation
Bei
Personen- und Institutionen-Evaluation ist der Zweck meist die Auswahl von Personen
und Gruppen zur Anstellung, Beförderung oder Belohnung bzw. Entlassung, Rückstufung
oder Bestrafung. Diese Art der Evaluation ist also "sanktionsbewehrt".
Beispiele:
Zulassung zum Studium;
Stellenbewerbung; Bewährungsaufstieg; leistungsbezogene Bezahlung von Professoren;
staatliche Zuschüsse für Schulen; Wettbewerb um Studierende/Schüler.
Bewertung von Schulen oder Universitäten für die Zuteilung von Finanzmitteln.
Dieser
Einsatz von Evaluationen wird hier nicht weiter behandelt. Es soll nur auf ein
Problem damit aufmerksam gemacht werden.
Bei
sanktionsbewehrten Evaluationen von Personen oder Institutionen im Bildungsbereich
besteht die Gefahr, dass die Zwecksetzung ungewollte Auswirkungen hat, die diesem
Zweck genau zuwider laufen, nämlich dass die Validität der Beobachtungen/Messungen
und die Qualität der evaluierten Leistungen beeinträchtigt werden.
Die
Validität der Beobachtungen bzw. Messungen wird dann beeinträchtigt,
wenn die evaluierten Personen und Institutionen es leichter empfinden, gute "Leistungen"
durch Tricks und Betrug zu erreichen als durch die Verbesserung des Unterrichts
und der Schulorganisation (die oft nur durch hohe Investitionen, bessere Lehrerausbildung
und -bezahlung zu erreichen ist), oder wenn sie dies als die einzige Möglichkeit
ansehen, Sanktionen zu vermeiden. Tatsächlich zeigen sich diese ungewollten
Auswirkungen täglich im Unterricht, wenn Schüler bei Klassenarbeiten
mogeln oder Lehrer versuchen, ihre Klasse mit "strengen" Noten zu disziplizieren.
Sie zeigen sich auch bei staatlich verordneten Evaluationen in den USA, wo solche
sie schon länger durchgeführt werden. Lehrer und ganze Schulkollegien
"verbessern" dort nachträglich die Tests ihrer Schüler, schicken
die "schlechteren" Schüler am Testtag nach hause, oder füllen
die Tests selbst aus; "schlechte" Schulen verweigern die Teilnahme an
Schulleistungsvergleichen oder werden gar nicht erst mit einbezogen (Owen,
2001; Amrein & Berliner, 2002;
Kohn, Web-Site).
Die
Qualität der Schulleistungen wird dann massiv beeinträchtigt, wenn Schüler,
Lehrer und ganze Schulsysteme sich darauf beschränken, nur die Fähigkeiten
zu üben, die in den Evaluations-Tests gemessen werden. Hierdurch wird die
Vielfalt der vermittelten Fachgebiete und Fähigkeiten stark eingeschränkt.
Man spricht hier von "teaching to the test" (Darling-Hammond,
2000, Shepard,
2001).
Interessanterweise
gehören in internationalen Schulleistungsvergleichen jene Länder zu
der Spitzengruppe, die Noten nur in den höheren Klassenstufen haben und die
Schulleistungstests eher zur Evaluation von Maßnahmen einsetzen als zur
Sanktionierung von Personen und Institutionen (... mehr
zu Schulleistungsvergleichen).
3.2
Methoden und Programmevaluation
(a)
Zweck ist die (vergleichende) Bewertung von pädagogischen und didaktischen
Methoden und Programmen im Bildungsbereich aufgrund ihrer Effektivität, Effizienz
und politisch-ethischen Wünschbarkeit.
Beispiele:
Nützt der
frühe Spracherwerb? Ist der Kommunikations-orientierte Fremdsprachenerwerb
effektiver als der traditionelle? Erzeugt der Problemorientierte Mathematikunterricht
ein besseres Verstehen? Verbessert die Wartezeitregel die Aufmerksamkeitsrate
und das aktive Lernen im Unterricht? Kann durch geeignete Fortbildung von Lehrern
die Zahl der Frühpensionierungen vermindert werden? Führen Methoden
wie Dilemma-Diskussion und Just community-Schule zu höherer moralischer Urteils-
und Diskursfähigkeit? etc.
(b)
Jede Evaluation muss sich ihrer Begrenztheit bewusst sein: Probleme sind u.a.
die Kriteriums- und die Zweckvalidität der Beobachtungs- und Messinstrumente;
die Testmotivation der Betroffenen; die Nachhaltigkeit der Effekte; die Ermittlung
der Wirtschaftlichkeit der Methoden und Programme (Effizienz).
Beispiele:
Halo-Effekte;
Fehleinschätzung von eigenen Lernergebnissen; die Messung von moralischen
Fähigkeiten mit Einstellungstests; vergängliche Effekte; "Schläfer"-Effekte;
Nebeneffekte.
4.
Der Evaluationsprozess
(im
Aufbau)
5.
Designs für Evaluation
Wenn
es Ziel einer Evaluation im Bildungsbereich ist, aufgrund von Beobachtungen und
Messwerte zuverlässige und gültige Urteile über die Wirksamkeit
(Effektivität) und den Nutzen (Effizienz) von Maßnahmen (z.B. neue
Unterrichtsmethoden, neue Änderungen im Bildungssystem) zu ermöglichen,
dann muss die Gewinnung der Daten entsprechend angelegt sein. Das heißt,
die Anlage (Design) der Evaluationsstudie muss so sein, dass die Schlussfolgerung,
die Daten der Studie würden eine bestimmte Annahme belegen, möglichst
klar und eindeutig belegt werden kann. Das heißt, ist die Evaluationsstudie
so angelegt,
- dass
die erbrachten Daten im Sinne der Fragestellung valide sind (Wurde überhaupt
das gemessen, was gemessen werden sollte?),
- und
dass alternative Annahmen, die zu gleichen Voraussagen kommen, aber sich auf andere
Voraussetzungen stützen, widerlegt werden können (Wurden die richtigen
Vergleich angestellt, um rivalisierende Erklärungen beurteilen zu können?)?
Im
ersten Fall sprechen wir von der Validität des inneren Designs der
Studie, im zweiten Fall von der Validität des äußeren Designs.
Beispiel:
Es soll evaluiert werden, ob das Bildungssystem des Landes X so gut ist, dass
seine Schüler vergleichsweise hohe Schulleistungen erbringen. Diese Annahme
wird durch die Annahme widersprochen, dass das Bildungssystem des Landes X "miserabel"
oder "marode" sei. Eine alternative Annahme kann sein, dass die Höhe
der Schulleistungen in einer vergleichenden Schulleistungsstudie weder die eine
noch die andere Annahme stützt, sondern eher damit zusammenhängt, wie
vertraut die Schüler mit Schulleistungstests sind. Eine Evaluationsstudie,
die hierauf eine Antwort zu geben versucht, müsste also so angelegt sein,
1. dass die berichteten Schulleistungswerte für die Frage "besser"
oder "schlechter" valide sind (z.B. sind die Schulleistungen repräsentativ
für das, was in der Schule unterrichtet wird?), und 2. dass gute oder schlechte
Ergebnisse eindeutig auf die Qualität des Unterrichts und nicht auf andere
Faktoren (wie Gesamtzahl der Schulstunden, soziale Selektion, Belastungen im Elternhaus,
Art der Leistungsmessung etc.) zurückgeführt werden können.
5.1
Was ist ein wissenschaftliches Experiment?
| Schwerkraft
so schnell wie Licht SEATTLE
ap Einstein hatte Recht: Die Geschwindigkeit der Schwerkraft entspricht der des
Lichts. Dies wurde jetzt mit Hilfe einer seltenen Planetenkonstellation nachgewiesen.
Edward Fomalout vom Nationalen Observatorium für Radioastronomie der USA
und Sergei Kopeikin von der Uni Missouri maßen dabei den Grad der Abweichung
des Lichts von einer fernen Sonne durch die Schwerkraft des Planeten Jupiter.
Albert Einstein, der grundlegende Theorien über Raum und Zeit im Universum
aufstellte, hatte angenommen, dass sich die Schwerkraft mit Lichtgeschwindigkeit
bewegt, also mit rund 300.000 Kilometern in der Sekunde. "Aber bislang hat
das noch nie jemand gemessen", sagte Kopeikin. Die Forscher nutzten bei ihrem
Experiment zehn Radioteleskope, um exakt zu messen, wie der Jupiter das Licht
des Sterns ablenkt, während er an ihm vorbeizieht. Die Möglichkeit zu
solchen Messungen bietet sich nur alle zehn Jahre. Quelle:
taz Nr. 6949 vom 9.1.2003, Seite 2, 32 Zeilen (Agenturbericht) |
Zweifellos wird hier von
einem sehr sorgfältig und aufwendig angelegten wissenschaftlichen Experiment
berichtet. Das Experiment zur exakten und validen Überprüfung einer
der bedeutendsten physikalischen Theorie der Neuzeit war so aufwendig und so wichtig,
dass es nicht nur in Wissenschaftlerkreisen beachtet wurde, sondern die Meldung
sogar den Weg in die Tagespresse fand.
Manche
Evaluationsforscher werden darin aber dennoch einige Dinge vermissen, auf die
in einschlägigen Methoden-Lehrbüchern sehr viel Wert gelegt wird, wie
"Manipulation" einer "unabhängigen Variablen",
"Experimental- und Kontrollgruppe" und "Randomisierung"
(die zufällig Aufteilung der Versuchsteilnehmer auf Experimental- und Kontrollgruppe).
Würde nicht der Name
von Einstein erwähnt und handelte es sich um eine Beobachtung aus dem Unterrichtsalltag
einer Schule, wäre das Experiment von diesen Forschern daher gar nicht als
wissenschaftliches Experiment anerkannt worden. Neuerdings macht das US-Bildungsministerium
sogar die Finanzierung und Anerkennung von Evaluationsstudien u.a. davon abhängig,
dass die Studienteilnehmer strikt zufällig auf Experimental- und Kontrollbedingungen
aufgeteilt werden (Slavin,
2002). Dies bedeutet u.a., dass alle ausgewählten Schüler
und Schulen an einer Studie teilnehmen müssen, weil ein nennenswerter
Ausfall den Zufall beeinträchtigen würde. In einem demokratischen Staat
lässt sich dies aber nur annähernd erreichen, wenn die Teilnehmer so
ausreichend gut bezahlt werden. Die dafür notwendigen Finanzbeträge
können so groß werden, dass die Erprobung neuer pädagogisch-didaktische
Ansätze nur noch von Personen und Institutionen durchgeführt werden
können, die über große Mittel verfügen oder aus diesen Aufwendungen
hohe Renditen erwarten. Unabhängige Forscher und kleine und Universitätsinstitute
werden dafür nicht die nötigen Mittel haben.
Es
ist daher absehbar, dass bestimmte, langfristig für den einzelnen und die
Gesellschaft wichtige Neuerungen im Schulsystem ausbleiben, wenn sie nicht in
randomisierten Evaluationsstudien überprüft werden können, weil
dies zu teuer ist oder weil dies prinzipiell nicht möglich ist, wie in dies
im Fall der Einstein-Theorie auch nicht möglich war. Dort war ja selbst eine
Manipulation nicht möglich, wie es sie von manchen für "echte"
Experimente gefordert wird.
Welche
Schwierigkeiten sich ergeben, wenn man die Evaluation von Bildungsprozessen nach
solche oberflächlichen Definitionen durchzuführen versucht, zeigt folgendes
Zitat.
"It is very difficult
to have a formal evaluation of a character education program with a true experimental
design because of the subject matter: students in schools with many different
teachers. Even when students are randomly assigned to experimental and control
classes, the 'control breaks down' as the year progresses, that is, students come
in, leave, or are absent; teachers differ uin their teaching techniques even when
using the same curriculum, and so forth. Additionally, there is a consensus that
because character develops incrementally over time, it is unrealistic to expect
an evaluation of a program after one year to prove anything definitively. Evaluation
of a character education program needs to have a longitudinal component. ...
A quasi-experimental design ... is the most
effective for the evaluation of character education programs. [It] uses two basic
strategies: the use of comparision groups and time-series analysis. Comparison
groups are not strict 'control groups' because it may not have been possible to
assign the members randomly, or to control for newcomers or leavers" (Murphy,
2002, S. 198-199) |
Was
also macht ein echtes, wissenschaftliches Experiment wirklich aus?
-
Fragestellung: "Riskant"
formulierte Hypothesen, die aus kohärenten und konsistenten Theorien abgeleitet
wurden, also eine präzise Fragestellung mit genauen Angaben über die
Vorhersagen, die aus bestimmten Annahmen folgen.
-
Anlage der Beobachtung (experimentelles Design): Eine Versuchsanlage und ein Messinstrument,
die genau die Bedingungen der Beobachtung realisieren, die in der Fragestellung
impliziert sind, und die eine eindeutige Bestätigung oder Widerlegung der
Vorhersagen erlauben.
Die
Probleme, von denen im Zitat oben gesprochen wird,
stellen sich bei dieser Definition ganz anders. Wichtig ist, dass zunächst
genauer gesagt wird, unter welchen Bedingungen (Altersbereich, Lehrerqualifikationen
etc.) eine bestimmte Methode der Moralerziehung wirksam sein soll, und welche
Fähigkeiten sie genau fördern soll. Wenn dieses präzise angegeben
ist, lassen sich Evaluationsdesigns erst auf ihre Validität hin beurteilen.
Es ist durchaus möglich, dass dafür keine Randomisierung
erforderlich ist, nämlich dann, wenn bereits ausreichend viele Untersuchungsdaten
vorliegen, die Auskunft über die "normale" Entwicklung dieser Fähigkeit
unter schulischen Bedingungen geben. Wichtiger ist es, dass die richtigen Vergleiche
angestellt werden und dass dafür genügend Daten mit ausreichender Qualität
(Validität) vorliegen (... mehr zu Randomisierung).
........
(wird noch ergänzt)
5.2
Vergleiche als Voraussetzung für die Messung der Wirksamkeit
und
den Nutzen von Maßnahmen
Um
die Wirksamkeit (Effektivität) und den Nutzen (Effizienz) von
Maßnahmen im Bildungsbereich valide einschätzen oder messen zu können,
sind immer Vergleiche notwendig. Nur mittels bestimmter Vergleiche von Beobachtungen
und Messwerten bekommen wir Informationen darüber,
-
ob
bestimmte Maßnahmen einen bestimmten Effekt gehabt haben (zum Beispiel
ob das Wissen auf dem Gebiet der Geographie oder die moralische Urteilsfähigkeit
einer Schulklasse zugenommen hat),
-
und
ob diese Maßnahmen einen Nutzen haben, d.h., ob die dadurch bewirkten
Verbesserungen (z.B. erhöhte Lernleistung der Schüler) in einem günstigen
Verhältnis zu den Kosten steht, die hierfür aufgebracht werden müssen.
Diese
Fragen sind nicht banal. Aus Vergleichen kann nicht immer der Schluss gezogen
werden, dass -- a) bei einem positiven Effekt -- die Maßnahme gewirkt hat
oder -- b) bei keinem oder einem negativem Effekt -- die Maßnahme erfolglos
war. Es kann nämlich sein, a) dass der Effekt auch aufgetreten wäre,
wenn keine Maßnahme durchgeführt worden wäre, weil andere Bildungseinflüsse
oder Selbstlernen für diese Steigerung der Messwerte verantwortlich sind,
oder b) dass im gleichen Zeitraum ein starkes Absinken der Messwerte zu beobachten
gewesen wären, wenn die Maßnahme nicht erfolgt wäre.
Beispiel:
in den ersten fünf Schuljahren und darüber hinaus sinkt die Schulfreude
stark ab (Helmke, 1993). Wenn ein
Schulprojekt dies verhindern und die Schulfreude auf dem Anfangsniveau halten
kann, ist dies als Erfolg anzusehen. Aus einem einfachen Vergleich von Vor- und
Nachtests kann dieser Erfolg aber nicht sichtbar gemacht werden. Hierzu benötigt
man Vergleichsdaten, die belegen können, dass die Schulfreude OHNE ein solches
Projekt stark abgenommen hätte.
Wie
wir unten noch eingehender zeigen werden, besteht das Minimal-Design für
die Evaluation von Maßnahmen und Methoden im Bildungsbereich in der Regel
aus folgenden Dingen:
-
einem
Vortest und einem Nachtest zur Bestimmung
unmittelbarer Effekte;
-
einem
weiteren Nachtest -- im Abstand von mindestens
einigen Wochen, besser noch einigen Monaten oder Jahren -- zur Bestimmung dauerhafter
oder nachhaltiger Effekte;
-
einer
"Kontroll- oder Vergleichsgruppe", die auch vor und nach der Maßnahme
untersucht wird; diese Kontrollgruppe sollte hinsichtlich wichtiger Merkmale der
Versuchsgruppe ähneln, was -- je nach Fragestellung und Umstände --
durch verschiedene Verfahren sicher gestellt werden kann (Zufallsaufteilung, Matching,
Normdatenvergleich, Replikationserhebung an derselben Gruppe, oder statistische
Verfahren); und
-
wenn
irgendwie möglich: Verbleib-
und Langzeitstudien zur Abklärung langfristiger Zielsetzungen.
Wenn
von diesem Minimaldesign aus triftigen Gründen abgewichen werden muss, sollte
dies in der Berichterstattung unter Angabe der Gründe dem Leser mitgeteilt
werden. Auch ein "sub-optimales" Evaluationsdesign kann wertvolle Hinweise
liefern; es kann aber zu großen Missverständnisse und Fehlschlüssen
führen, wenn seine Begrenztheit nicht bewusst ist.
Die
verschiedenen Möglichkeiten des Vergleichs zur Abschätzungen der Effektstärke
und des Nutzens einer Maßnahme wird unten eingehender diskutiert.
Hinweis:
Momentaufnahmen ohne Vortest und ohne Querschnittvergleiche werden hier
nicht behandelt, da sich daraus in der Regel keine wissenschaftlich fundierten
Evaluationen ableiten lassen. Aus ihr können selten Rückschlüsse
auf die Wirksamkeit bestimmter bildungspolitischer Maßnahmen oder pädagogisch-didaktischer
Methoden gezogen werden. Solche Momentaufnahmen haben ihren Platz eher in anderen
Kontexten, etwa bei Sportveranstaltungen oder Unterhaltungssendungen, wo es gilt,
einen "Sieger" oder "Verlierer" zu ermitteln, nicht aber im
Bereich der Bildung, wo es vor allem darauf ankommen sollte, Unterrichtsmethoden
und Schulstrukturen zu verbessern.
5.3
Diskussion verschiedener Evaluations-Designs
Im
folgenden werden verschiedene Designs für Evaluationsstudie unter dem Gesichtspunkt
der Methoden- oder Programm-Evaluation eingehender vorgestellt und diskutiert.
(Inwieweit sie sich auch für Personen- und Institutionen-Evaluation eigenen,
soll hier nicht weiter erörtet werden.)
Überblick
über mögliche Evaluations-Designs:
| | Testzeitpunkt | | |
| | Vorher | Nachher | Später | Vergleichs-
gruppe | Zufallsaufteilung (Randomisierung) |
| Post-Test o. Vergleich | | Ja | | | |
| Post-Test m.Vergleich | | Ja | | Ja | |
| Pre-Post-Test o.V. | Ja | Ja | | | |
| Querschnitt-Studie | Ja,
im bedingten Sinne | Ja, möglich | |
|
Echte Evaluations-Designs |
| Pre-Post-Test m.V. | Ja | Ja | | Ja | |
| Pre-Post-Post | Ja | Ja | Ja | Nein/Ja | |
| Pre-Post(-Post) m. Randomisierung | Ja | Ja | Nein/Ja | Ja | Ja |
| Längsschnitt | Ja | Ja | Mehrfach | Nein/Ja | Nein/Ja |
| |
Wenn
die Wirkung einer neuen Unterrichtsmethode auf bestimmte Kriterienvariablen (z.B.
Zunahme der Mathematikfähigkeit bei Schülern in der Mittelstufe) untersucht
werden soll, dann kann das nicht allein durch einen Voher-Nachher-Vergleich geschehen,
da es nicht klar ist, ob dafür allein die neue Methode verantwortlich ist.
Es ist z.B. durchaus wahrscheinlich ist, dass die Schüler auch ohne die neue
Methode eine Zunahme aufweisen. Um solche alternativen Erklärungen für
einen beobachteten Effekt ausschließen zu können, benötigt man
geeignete Vergleichsgruppen.
Es
gibt verschiedene Arten von Vergleichsgruppen. Die vier gebräuchlichsten
sind:
-
Vergleiche
mit sich selbst: Vor Beginn einer Maßnahme wird durch einen Vorher-Nachher-Erhebung
festgestellt, ob und wie stark sich in den Schulen oder Schülergruppen das
Merkmal "auf natürliche Weise" (also ohne die projektierte Maßnahme)
über einen bestimmten Zeitraum ändert, und erst dann wird im selben
Zeitraum festgestellt, ob die Maßnahme einen Einfluss auf die Änderungsrate
hat. Diese Vergleiche eignen sich sehr gut für die Evaluation in Bildungsbereich,
da eine maximale Vergleichbarkeit möglich ist. Dadurch kann ein Hawthorne-Effekt
ausgeschlossen werden, bei dem nicht die eigentliche Maßnahme, sondern Begleitumstände
wie die durch die Untersuchung gegebene soziale Aufmerksamkeit wirksam sind. Durch
die Verbindung des Vorher-Nachher-Designs mit Querschnitt-Erhebungen lässt
sich ausschließen, dass Kohorten-Effekte für
die festgestellen Änderungen verantwortlich sind. Nachteil: Lehrplanspezifische
Methoden lassen sich nur schwer oder gar nicht sequentiell vergleichen.
-
Gepaarte Vergleichsgruppe
(matched sample), die auf der Basis von bestimmten Vergleichskriterien ausgewählt
und in die Untersuchung mit einbezogen werden. Es gibt keine allgemein gültigen
Kriterien, aufgrund welcher Merkmale die Paarung vorgenommen werden sollte. Es
liegt nahe, dafür die Messvariable zu nehmen (d.h., in unserem Beispiel oben
sollten die beiden Gruppen hinsichtlich des Anfangsniveaus an Schulfreude möglichst
gleich sein, da sonst mit sogenannten Decken- oder Boden-Effekten zu rechnen ist),
aber auch andere Kriterien könnten oder sollten herangezogen werden, wenn
es hinweise gibt, dass diese das Ergebnis auch stark beeinflussen können,
wie z.B. das Geschlecht der Schüler oder ihre soziale Herkunft.
-
Repräsentative Gruppen,
von denen Vergleichsmessungen vorliegen, die auf der Basis von bestimmten Vergleichskriterien
nachträglich der Untersuchungsgruppe zugeordnet werden. Welche Messgrößen
(Variablen) hierzu verwendet werden, ist ebenso wie bei den gepaarten Vergleichsgruppen
nicht allgemeingültig zu bestimmen, sondern muss von Fall zu Fall entschieden
und begründet werden. Ein großer Vorteil solcher Vergleiche liegt darin,
dass sich die Vergleichbarkeit nach mehreren Gesichtspunkten optimieren lässt.
Diese Art von Vergleich eignet sich besonders in Fällen, in denen bereits
viele Vergleichsstudie auf großer Samplebasis vorliegen.
-
Statistische Angleichung der Gruppen:
Durch Ko-Varianzanalysen, Berechnung von Partial-Korrelationen und andere statistische
Verfahren lassen sich die Veränderungen in verschiedenen Experimental- und
Kontrollgruppen nachträglich vergleichbar machen. Welche Messgrößen
(Variablen) hierzu verwendet werden, ist ebenso wie bei den gepaarten Vergleichsgruppen
nicht allgemeingültig zu bestimmen, sondern muss von Fall zu Fall entschieden
und begründet werden. Die weit verbreitete Praxis, hierfür einfach leicht
erhebbare Messgröße wie das Geschlecht und die soziale Herkunft zu
benutzen, ist häufig inhaltlich nicht zu begründen.
-
Zufallsgesteuerte Vergleichsgruppe:
die Vergleichsgruppe wird per Zufall aus derselben Grundgesamtheit gewählt
wie die Versuchsgruppe, die die Maßnahme erhält. Diese Art der Erzeugung
von Vergleichsgruppen gilt in vielen Lehrbüchern als der "Königsweg",
da damit angeblich ALLE "störenden" Faktoren ausgeschlossen werden
können, d.h. dass damit Änderungen in der Experimentalgruppe (die über
die Änderungen in der Vergleichsgruppe hinausgehen) eindeutig auf
die zu evaluierende Maßnahme zurück geführt werden können.
Diese Aussage mag in der Agrarwissenschaft stimmen, aus der viele statistische
Verfahren stammen, die in den Sozialwissenschaften heute angewandt werden. Aber
in Studien über Menschen und menschlichen Einrichtungen stimmt diese Aussage
nur in seltenen Fällen:
-
Menschen
sind soziale Wesen. Die "zufällige" Aufteilung auf verschiedene
Untersuchungsgruppen bedeutet oft ein Zerschneiden sozialer Bezüge, die mit
den untersuchten Effekten direkt in einer Kausalbeziehung stehen können.
Beispiel: durch die Neueinteilung der Schüler zu verschiedenen Klassen werden
gewachsenen Freundschaftsstrukturen zerstört und dadurch vermutlich die Schulfreude
getrübt, was sich in der Experimentalgruppe so stark auswirken kann, dass
die Maßnahme zur Förderung der Schulfreude konterkariert wird.
-
Mit einer Zufallsaufteilung können
nur bestimmte, aber niemals alle denkbaren Faktoren ausgeschlossen werden, die
das Ergebnis einer Maßnahme beeinflussen können, vor allem nicht die
sogenannten Randbedingungen eines Experiments. Nicht ausschließen kann man
z.B. den sog. Hawthorne-Effekt (s.o.). Auch "ökologische" Effekte
sind damit schwer abschätzbar. Es z.B. kann sein, dass eine bestimme Maßnahme
die Schulfreude von Kindern in einem Flächenstaat wie Bayern erhält,
aber nicht in einem Stadtstaat wie Hamburg oder in einer ganz anderen Kultur.
Um hierüber Auskunft zu erhalten, sind Replikationsstudien in anderen "ökologischen"
Kontexten notwendig notwendig. Letzte Gewissheit ist nicht möglich. So etwas
wie ein "Entscheidungs-Experiment", mit dem eine Hypothese über
bestimmte Ursachen-Wirkungs-Beziehungen völlig eindeutig und für immer
entschieden werden kann, kann es nicht geben (Popper,
1968).
-
Kombinierte
Längs- und Querschnittuntersuchungen haben sich als mindestens gleichwertigen
Ersatz für Zufallsaufteilungen (Randomisierungen) und in mancher Hinsicht
sogar als nützlicher erwiesen und sind, wenn gewählt werden muss, diesen
vorzuziehen (Baltes, 1968).
Aufgabe:
Sammeln Sie einige
Vor- und Nachteile für jede der obigen Vergleichsgruppen.
5.3.1
Post-Test ohne Vergleichs- (Kontroll-) gruppe
Dieses
Design hat einen sehr begrenzten Anwendungsbereich. Bei kriteriums-orientierten
Tests (criterion-referenced tests) kann sein Einsatz sinnvoll sein. In
vielen Fällen sind die Voraussetzungen für dieses Design nicht gegeben;
in solchen Fällen ist es völlig wertlos.
Übungsfragen:
Können folgende
Annahmen oder Behauptungen mit dem Post-Test-Design angemessen überprüft
werden? Warum? Geben Sie bitte Gründe an.
Beispiel 1: Es wird angenommen,
dass Grundschüler der ersten Klasse bis Ende des Schuljahres das ganze Alphabet
lesen und in Druckschrift schreiben können.
Beispiel 2: Es wird behauptet,
die Grundschule A unterrichtet das Alphabet effektiver als die Grundschule B.
Lösung
5.3.2
Post-Test mit Vergleichsgruppen
Auch
dieses Design hat einen sehr eingeschränkten Anwendungsbereich. Es kann eingesetzt
werden, wenn es darum geht, verschiedene Methoden oder Programme zu vergleichen,
bei denen die Charakteristika und die Ausgangslage der Teilnehmer nicht interessieren
(was selten der Fall ist). Man kann anhand eines solchen Designs beschreiben,
in welchem System Teilnehmer besser abschneiden, aber nicht, welche Faktoren für
das Abschneiden verantwortlich sind.
Im Bereich des Sports kann man als Beispiel
die Frage nennen, wer einen offenen Volkslauf gewinnt, bei dem alle teilnehmen
können. Die Frage, welche Faktoren (Alter, Training, Geschlecht, Ernährung,
Veranlagung etc.) für ein gutes Abschneiden maßgeblich sind, lässt
sich mit reinen Post-Test-Designs nicht beantworten.
Übungsfragen
a) Ein Beispiel für
ein solches Design ist die Studie PISA-2000, in der in
verschiedenen Ländern gemessen wird, wie gut 15-jährige bei Mathematik-,
Naturkunde- und "Lesefähigkeits"-Tests abschneiden. Welche der
folgenden Schlussfolgerungen können aus diesem Design theoretisch gezogen
werden:
- wie effektiv das deutsche Bildungssystem im Vergleich zu anderen
ist,
- wie effektiv bestimmte didaktische Methoden sind,
- ob deutsche
Schüler bei Schulleistungstests genetisch benachteiligt sind.
b)
Suchen Sie einen Anwendungsbeispiel, wofür sich dieses Design eignet.
Literatur: Baumert et al. (2001)
Lösung
5.3.3
Querschnitt-Untersuchungen.
Wenn
aus zeitlichen und organisatorischen Gründen keine Vorher-Nachherstudien
möglich sind, können Querschnittdesigns als eine Annäherung hieran
gelten. Zwar stellen sie keine "echten" Evaluationsdesigns dar, da die
Wirkung bestimmter Maßnahmen nicht an ein und derselben Personengruppe überprüft
wird, sondern mehrere Alterskohorten oder Generationen untersucht werden, die
von der in Frage stehenden Maßnahme in unterschiedlicher Weise betroffen
waren, so dass indirekt -- unter Zuhilfenahme der Annahme, dass keine anderen
systematischen Einflüsse bestimmte Veränderungen erklären können
-- die Wirkung der Maßnahme abgeschätzt werden kann.
Zum
Beispiel können die Schulleistungsunterschiede von Schülern der fünften,
siebten und neunten Klasse als Grundlage dienen, um den Wirkungsgrad des Unterrichts
an Schulen zwischen 5 und 9. Klasse zu schätzen. Wenn man dies in mehreren
Ländern gleichzeitig tut, kann man mit einem solchen Evaluationsdesign den
Wirkungsgrad verschiedener Schulsysteme abschätzen; allerdings immer nur
unter der Voraussetzung, dass andere mögliche Einflussfaktoren wie die spezifischen
Erfahrungen bestimmter Alterskohorten keinen nennenswerten Einfluss auf
das Ergebnis hatten.
Bei
eng beieinander liegenden Alterskohorten erscheint eine solche Annahme meistens
plausibel. Wenn es sich um weit auseinander liegende Kohorten handelt, wie zum
Beispiel bei dem Vergleich der Schulleistungen von 15- und 50-jährigen ist
das kaum mehr plausibel. Zu viele Dinge haben geändert, seit die heute 50-Jährigen
zur Schule gingen: die Lage der Eltern, der allgemeine Wohlstand, der Unterrichtsstil,
die Lernanforderungen, der Einfluss der Medien etc. Dies schließt aber nicht
aus, dass bestimmte Fragestellungen ein solches Erhebungsdesign als angemessen
und begründet erscheinen lassen können.
Merke:
Der Begriff "Querschnittstudie" wird manchmal auch für reine Posttest-Designs
mit einer einzigen Altersgruppe verwendet. Dies ist eher verwirrend und entspricht
nicht dem allgemeinen Sprachgebrauch in der Evaluationsforschung. Man spricht
in solchen Fällen besser von "Momentaufnahmen" oder "Vergleichsstudien".
-------------
Echte Evaluationsdesigns --------------
5.3.4
Pre-Post-Test mit Vergleichs-Gruppe
Jede
Frage nach der Effektivität einer Methode (bzw. nach der Lernfähigkeit
einer Person oder einer Gruppe) setzt als Mindestanforderung ein Pre-Post-Test-Design
voraus. In Begriffen wie "Effizienz" und "Lernfähigkeit"
steckt die Frage nach einer Veränderung oder Entwicklung. Diese kann nur
beantwortet werden, wenn man die interessierenden Merkmale (Leistungen, Fähigkeiten,
Einstellungen etc.) über die Zeit verfolgt, und zwar so dass der Einfluss
der Methode von anderen Einflüssen unterscheiden kann. Die Mindestanforderung
ist der Vergleich von Beobachtungen vor und nach Anwendung einer bestimmten Methode
(oder der Einführung eines bestimmten Programms).
Der
renommierte Psychologe und Bildungsexperte Franz-Emanuel Weinert vom Max-Planck-Institut
für Psychologie in München bemerkt dazu:
"Internationale Vergleichsuntersuchungen
(z.B. TIMSS und PISA) .... schaffen Orientierungswissen, das viele praktisch relevante
Informationen enthält, wichtige Vergleiche erlaubt und zur Bildung von Planungshypothesen
beiträgt, in der Regel aber nicht geeignet ist, bildungspolitische Entscheidungen
... direkt zu fundieren oder zu steuern (Trier, 1995). Dazu bedarf es spezifisch
geplanter Untersuchungen, häufig in Form von evaluierten Modellversuchen
(denen bisher allerdings oft die erforderliche Strenge der Untersuchungsplanung,
die Qualität der Messverfahren und die notwendigen Vergleichsstichproben
fehlen)." (Weinert, 2001, S. 28-29)
Übungsfragen:
a) Welche der folgenden
Evaluationsfragen erfordern den Einsatz mindestens eine Pre-Post-Test-Designs?
Warum bzw. warum nicht?
1. Führt die Ganzwort-Methode zu schnellerem
Leselernen als die traditionelle, zerlegende Methode?
2. Sind Gesamtschulen
effizienter bei der Förderung moralisch-demokratischer Fähigkeiten als
Gymnasien?
3. Gleichen sich die Mathematikkenntnisse der Schüler einer
Klasse gegen Ende des Schuljahres einander an?
4. Lässt sich der Aufmerksamkeitsgrad
in einer Klasse deutlich steigern, wenn der Lehrer/die Lehrerin die Wartezeit-Regel
verwendet?
5. Kennen deutsche Abiturienten alle Mitglieder der Bundesregierung?
b) Warum warnt Weinert (2001) davor, Schulvergleichsstudien wie TIMSS und PISA
dazu zu benutzen, bildungspolitische Maßnahmen zu fundieren und zu steuern?
Welche Evaluationsdesigns schlägt er stattdessen vor?
Lösung
5.3.5
Pre-Post-Post-Test ohne/mit Vergleichsgruppe
Wenn
die Nachhaltigkeit oder Stabilität von Effekten in die Evaluation
mit einbezogen werden soll, ist ein verzögerter Nach-Nachtest notwendig.
Es hängt von der erwarteten Nachhaltigkeit ab, wieviel Zeit zwischen Post-Test
und Post-Post-Test liegen soll. Soll nur die Vermutung überprüft werden,
dass es sich um sehr flüchtige Effekte handelt, genügt ein relativ kurzer
Zeitraum von wenigen Wochen oder Monaten.
Es kann aber auch ein sehr langer
Zeitraum erforderlich sein, wenn zum Beispiel von latentem Lernen ausgegangen
werden muss oder wenn bestimmte Effekte sich erst zeigen können in einer
bestimmten Lebenslage der Test-Teilnehmer zeigen können.
Übungsfragen
Bei welchen der folgenden
Fragestellungen ist mindestens ein Post-Post-Test-Design notwendig und wie lange
etwa sollte der Abstand zwischen den beiden Post-Tests sein, um gültige Aussagen
machen zu können? Warum?
a) Der Einfluss des elterlichen Kommunikationsstil
mit ihren Kindern zeigt sich erst, wenn die Kinder zu jungen Erwachsenen wurden.
b) Durch vermehrten Praxisbezug im Studium machen Hochschulabsolventen in ihrem
Beruf schneller Karriere.
c) Die Methode der Dilemma-Diskussion regt die Entwicklung
der individuellen Urteilsfähigkeit an.
d) Wenn man Kinder bis zum 8.
Schuljahr nicht benotet, fällt es ihnen schwer, sich später auf den
Wettbewerb in den oberen Schulklassen einzustellen.
e) Mit der richtigen Vorbereitung
nach der Methode X können Schüler ihre Klassenarbeiten besser bewältigen.
Lösung
5.3.6
Randomisierung
(in Arbeit)
Viele
Autoren halten die zufällige Aufteilung (Randomisierung) von Versuchspersonen
auf die Experimental- und Kontrollgruppen in einer Evaluationsstudie für
absolut notwendig und unverzichtbar, damit eine solche Studie eindeutige Hinweise
auf die kausale Wirkung der in Frage stehenden Maßnahme (neue Unterrichtsmethoden
und -inhalte, Strukturreformen, etc.) eindeutig belegen kann (siehe Campbell
& Stanley, 1966;
...).
Diese Auffassung
ist historisch aus agrarwissenschaftlichen Studien zur Effektivität von Düngemitteln
und Neuzüchtungen entstanden und von da auf psychologische und pädagogische
Studien übertragen worden.
Die
Zufallsaufteilung von Versuchspersonen auf die Untersuchungsgruppen ist unter
bestimmten Bedingungen sicher sinnvoll und hilfreich, um zu eindeutigen Schlussfolgerungen
über die Wirksamkeit oder Unwirksamkeit bestimmter Maßnahmen zu gelangen.
Es muss jedoch bezweifelt werden,
- ob
diese Art der Zufallsaufteilung die einzig mögliche und sinnvolle ist,
-
ob Zufallsaufteilungen wirklich die Eindeutigkeit von Schlussfolgerungen aus empirischen
Studien zu garantieren vermag, oder
-
ob Zufallsaufteilungen die Validität von Schlussfolgerungen nicht auch beeinträchtigen
können (siehe oben).
a)
Gründe für den Einsatz von Randomisierung in Experimenten
Um
zu verstehen, welche Rolle Randomisierung bei Experimenten und Evaluationsstudien
spielen, muss man sich der Funktion von Experimenten vergegenwärtigen.
Ein
Experiment dient dazu, die Frage zu beantworten, ob eine bestimmte Theorie über
empirische Sachverhalte anderen Theorien überlegen ist. Dies ist dann der
Fall, (a) wenn die Ergebnisse eines Experiments mit dieser Theorie (und den aus
ihr abgeleiteten Hypothesen gut übereinstimmt) und (b) wenn Erklärungen
bzw. Hypothesen, die aus rivalisierenden Theorien abgeleitet werden können,
gleichzeitig widerlegt oder ausgeschlossen werden können. Experimente können
niemals einen endgültigen Beweis für die Richtigkeit einer Theorie liefern,
aber bei geeigneter Anlage können Experimente die Überlegenheit einer
Theorie über bestimmte andere (ältere) Theorien liefern und damit zum
Fortschritt der Wissenschaft und der einschlägigen Praxis beitragen.
"Scientific
studies should be carefully designed so that each potential research outcome will,
as nearly as possible, exclude one or more alternative hypothesis. To provide
an awareness of whether or not we have designed a study that may possibly not
turn out, Platt recommended asking ourselves 'The Questions' in relation to research
designs. When evaluating a research design, we should ask, 'What hypothesis does
this experiment disprove?' and when building our theories, we should ask, 'What
experiment will disprove this hypothesis?' "
(Kromrey, J.D., 1993, Ethics and data analysis. Educational Researcher, 22,
24-27, p. 26)
Ein
Experiment dient der "Prüfung einer Kausalhypothese mit Hilfe einer
kontrollierten und einen Unterschied schaffenden Anordnung."
(Greenwood, E., 1975. Das Experiment in der Soziologie.
In: R. König, Eid., Beobachtung und Experiment in der Sozialforschung,
pp. 171-220. Köln: Kiepenheuer & Witsch; p. 178).
Ähnlich
äußert sich Phillips zur Funktion des Experiments: "By 'experimental'
I am not referring only to the particular technique of data collection and analysis
known as the experiment but, more broadly, to the scientist's active testing of
his ideas, using whatever methods of data collection he deems appropriate."
(Phillips, B.S.,
1976, Social research. Strategy and tactics. New York Macmillan. 3rd edition.
p. 15).
Es
geht also nicht darum, alle alternativen Hypothesen auszuschließen,
die einen bestimmen Befunde erklären können. Es genügt, wenn wir
eine oder mehrere alternative Hypothesen ausschließen können, nämlich
jene, die sich aus einer gut begründeten alternativen Theorie ableiten können.
....
(in Arbeit)
b) Andere Arten
der Randomisierung
c) Kosten
der Randomisierung
d) Grenzen
der Randomisierung
e) Gefahren
der Randomisierung
"Umgekehrt
ist die Basis der neisten [...] Theorien des Verhaltens [...] die experimentelle
Untersuchung. Nach ihrer Grundkonzeption ist sie kausalanalytische Untersuchung,
die durch den Vorrang der Manipulation bzw. Kontrolle von unabhängigen Variablen
gerade dem nicht Raum gibt, was für eine Handlungskonzeption menschlicher
Tätigkeit unumgänglich ist: dem Dialog mit dem andern, der alleine die
Übereinstimmung über das Handlungsziel und das Erreichen dieses Ziels
fundieren kann." (Graumann,
1980, S. 27)
5.3.7
Verbleib- und Längsschnittstudien
(in Arbeit)
5.3.8
Typen von nicht-experimenteller Forschung
Zum
Vergleich zu den oben besprochenen Typen der Evaluationsforschung seien hier die
Typen der "nicht-experimentellen, quantitativen Forschung" von Johnson
(2001) in der folgenden Übersicht dargestellt. Der Typ "Evaluationsforschung"
ist bei Johnson nicht aufgeführt.
Typen
der nicht-experimentellen, quantitativen Forschung
von Burke Johnson, 2001
(PDF-Datei)
*
und der Evaluationsforschung |
|
Zeitdimension |
| Forschungsziel | Retrospektiv | Cross-sectional | Longitudinal |
| Beschreibend | Typ
1 | Typ
2 | Typ
3 |
| Vorhersagend | Typ
4 | Typ
5 | Typ
6 |
| Erklärend | Typ
7 | Typ
8 | Typ
9 |
| Evaluation | ? | ? | ? |
Source:
Johnson , B. (2001). Toward a new classification of nonexperimental quantitative
research. Educational Researcher, 30 (2), 3-13.
Reprint also available from
http://www.aera.net/ |
6.
Kriterien und Instrumente
Kriterien
für die Evaluation werden durch die übergeordneten Zwecke einer Evaluation
begründet, müssen aber -- aus Kosten- und Zeitgründen -- viel konkreter
formuliert werden und müssen sich in der Regel auf einen Teilbereich der
Zwecke beschränken.
Beispiel:
In der PISA-Studie, deren Zweck es ist, nationale Bildungssystem der Teilnehmerstaaten
zu evaluieren, beschränkt man sich auf drei Kriterien:
- Lesefähigkeit
- Mathematik
und
- Naturwissenschaften
Die
Beobachtungs- und Messinstrumente stellen die Konkretisierung von Evaluationskriterien
dar. Oft bedeuten sie gegenüber den Kriterien eine erneute Eingrenzung, auch
wenn es sich meistens nicht um ein einziges Instrument, sondern um ganze Bündel
von Instrumenten handelt.
Als Beispiel
soll die Evaluation von Lehrveranstaltungen dienen. Das Instrumentenbündel
kann aus folgenden Versatzteilen zusammengestellt bestehen (unerlässliche,
aber bislang oft vernachlässigte Teile sind fett gedruckt):
| | |
1. Persönliche Angaben, subjektive Lernziele
und Erwartungen der Lernenden an das Lernergebnis in der zu evaluierenden Lerneinheit |
| | | 2.
Vorbildung und Vorerfahrungen der Lernenden;
Lernstile |
| | | 3.
Fachliche und überfachliche Kenntnisse
und Fähigkeiten |
| | | 4.
Subjektive Evaluation des Fähigkeitszuwachses
der Lernenden (Beispiel) |
| | | 5.
Subjektive Lehr-Evaluation durch die Lernenden |
| | | 6.
Beobachtungen der Lehrenden selbst (auch Video-unterstützt)
|
| | | 7.
Beobachtungen von Peers, externen Experten für
das Lehr- oder Unterrichtsfach und Experten für Lehren und Lernen (Allg.
Didaktik, Lernpsychologie, Fachdidaktik) |
| | |
Beispiel
für einen Vortest (Pädagogische Psychologie, Moralische Urteilsfähigkeit) |
| | | Beispiel
für einen Nachtest (Pädagogische Psychologie, Moralische Urteilsfähigkeit)
|
Die
Instrumentteile 1. bis 3. finden Einsatz im
Vortest, die Teile 3. bis 7. im
Nachtest.
Alle
Instrumente sollten ausreichend vorerprobt sein. An die Vorerprobung von
Instrumenten zur Erfassung von Fachkenntnissen und -fähigkeiten sind hohe
Anforderungen zu stellen.
Die Auswahl der Instrumente sollte auf der
Grundlage einer klaren Zieldefinition (Was soll in dieser Institution bzw. diesem
Kurs erreicht werden?) und von Forschungsergebnissen geschehen.
Merke:
Evaluationsinstrumente, in denen nicht nach dem Lernzuwachs gefragt wird und keine
Messung von Lernzuwachs erfolgt, sind für den Einsatz in Bildungsinstitutionen
kaum geeignet.
Schulen
und Hochschulen sowie andere (Bildungs-)Organisationen werden in erster Linie
daran gemessen, welche Fähigkeiten sie vermitteln. Bei
Evaluationen müssen daher Fähigkeiten im Mittelpunkt stehen und können
keineswegs durch Selbsteinschätzungen (für wie fähig man sich hält)
oder durch die Einschätzung der Institution (für wie effektiv man sie
hält) ersetzt werden. Solche Einschätzungen und Einstellungen können
nur gering oder gar nicht mit der tatsächlichen Leistung der Organisation
korrelieren. Sie können diese stark über- oder unterschätzen.
Es
gibt Hinweise dafür, dass zum Beispiel Schüler mit zunehmenden Alter
die Schule kritischer und negativer bewerten und weniger zufrieden sind (Helmke,
1993). Andererseits weisen Berichte aus den USA und anderen Ländern mit stark
differenzierten, privaten Bildungsangeboten darauf hin, dass die Schüler
und Studierenden ihre eigene Institution umso leistungsfähiger beurteilen,
desto teuerer sie sind. Das dürfte weniger seinen Grund in der tatsächlichen
Leistungsfähigkeit dieser Institutionen haben, als darin, dass sie der gute
Ruf dieser Institutionen einen wesentlichen Teil des Gegenwertes zu den hohen
Studiengebühren darstellt. So zeigte sich zum Beispiel in den USA, dass --
entgegen ihrem Ruf -- die billigsten "Community Colleges", die vor allem
für Afro-Amerikaner offen stehen, ebenso viel Wissen und Fähigkeiten
vermitteln wie die teuersten Elite-Universitäten (Pascarella et al., 1995).
Gleichwohl
ist es wichtig, dass im Rahmen einer Evaluation auch die subjektiven Einschätzungen
der Beurteilten eingeholt und mit ihnen diskutiert wird, vor allem dann, wenn
eine entwicklungsorientierte Evaluation durchgeführt
wird.
6.3
Fähigkeiten (Kompetenzen)
Weinert
(2001): "Als Erträge
des schulischen Unterrichts kann man zwischen folgenden Kompetenzen unterscheiden:
- fachliche Kompetenzen (z. B. physikalischer, fremdsprachlicher, musikalischer
Art),
- fachübergreifende Kompetenzen (z. B. Problemlösen, Teamfähigkeit),
- Handlungskompetenzen, die neben kognitiven auch soziale, motivationale, volitionale
und oft moralische Kompetenzen enthalten und es erlauben, erworbene Kenntnisse
und Fertigkeiten in sehr unterschiedlichen Lebenssituationen erfolgreich, aber
auch verantwortlich zu nutzen.
Es ist unbestritten, dass diese Klassen von
Kompetenzen für ein gutes und erfolgreiches Leben innerhalb wie außerhalb
der Schule notwendig sind. Prioritätssetzungen zwischen diesen Kompetenzen
oder gar die Ablehnung einzelner Kompetenzbereiche (z. B. der fachlichen Kenntnisse)
haben sich im Lichte des kognitionspsychologischen Erkenntnisstandes als höchst
problematisch erwiesen." (S. 28)
Übungsfragen:
a) Was unterscheidet
eine Fähigkeit von einer Einstellung? Woran lässt sich der Unterschied
empirisch festmachen?
b) Wie
kann man eine Fähigkeit so definieren, dass sie beobachtbar oder messbar
ist?
6.4
Einstellungen und Einschätzungen
(in
Arbeit)
7.
Auswertung und Berichterstattung
Evaluationsbericht
- Der Bericht muss alle Angaben enthalten,
die für eine vollständige Replikation der Evaluation notwendig sind
(inklusive Auswertung)
- Der Bericht
muss in so verfasst sein, dass andere Personen (einschließlich der Lernenden)
ihn verstehen, kritisch kommentieren und Schlussfolgerungen für die eigene
Lehre ziehen können.
- Bei
Effekten soll immer die Effektstärke
und, wenn möglich, das Ausmaß an absoluten Veränderungen
angegeben werden. Die Angabe von statistischen "Signifikanzen"
ist unzureichend und heute nicht mehr akzeptabel.
Merke:
Berichte, in denen Angaben zur Effektstärke und Rohwerte (absolute und/oder
relative Antwort- und Lösungshäufigkeiten) fehlen, und deren zentralen
Kennwerte nicht so erklärt sind, dass sie von Laien mit erfolgreicher Absolvierung
der Pflichtschule verstanden werden können, sind sehr Frag-würdige
Grundlagen für bildungspolitische Entscheidungen.
Statistische
Signifikanz
Empfehlungen
von Bruce Thompson (1994) zur Rolle von statistischen Signifikanztests in der
Bildungsforschung:
"Zu
wenige Forscher verstehen, was statistische Signifikanztests tun und was sie nicht
tun, und folglich werden ihre Befunde falsch interpretiert. Noch häufiger
verstehen Forscher Elemente des Signifikanztestens, aber das Konzept ist nicht
in ihre Forschung integriert. Zum Beispiel wird der Einfluss der Stichprobengröße
von einem Forscher erkannt, aber diese Einsicht wird nicht vermittelt, wenn das
Ergebnis einer Studie mit vielen Tausend Versuchsteilnehmern interpretiert wird."
... mehr
(in Englisch; Passwort notwendig).
Schon
durch die ungenaue Sprache wird viel Verwirrung gestiftet. Zumeist ist mit "signifikant"
nur "statistisch signifikant" gemeint, aber nicht psychologisch oder
pädagogisch signifikant. Beides hat zunächst einmal nichts miteinander
zu tun.
Was psychologisch und pädagogisch bedeutsam ist, muss theoretisch
und/oder praktisch begründet werden. Statistische Signifikanz kann bei der
Beurteilung der psychologisch-pädagogischen Signifikanz eine Rolle spielen,
muss es aber nicht. Die inhaltliche Bedeutsamkeit einer Untersuchung hängt
selten davon ab, dass irgendein ein Unterschied gefunden wurde. Bei bestimmten
Fragestellungen können sehr geringe Unterschiede bedeutsam sein, bei anderen
nur große.
Merke: Die statistische Signifikanz wird vom Umfang der Stichprobe
und der Präzision des Messinstruments bestimmt. Bei sehr großen Stichproben
und sehr genauen Instrumenten wird jeder noch so kleine Unterschied "signifikant",
bei kleinen Stichproben werden oft wirklich bedeutsame Zusammenhänge übersehen,
weil sie statistisch nicht "signifikant" werden können. ... mehr
Daher sollten in Untersuchungen auch relative und absolute Effektstärken
berechnet und berichtet werden ... mehr.
Literatur
Gigerenzer,
G. (1991). Messen und Modellbildung in der Psychologie. München.
Hays,
W. (1963). Statistics for psychologists. New York.
Thompson,
B. (1996). AERA editorial policies regarding statistical significance testing:
three suggested reforms. Educational Researcher, 25(2), 26-30.
Wainer
& Robinson (2003). Shaping up the practice of null-hypothesis signifcance
testing. Educational Researcher, 32(7), 22-30.
Westermann,
R. (2000). Wissenschaftstheorie und Experimentalmethodik. Ein Lehrbuch zur Psychologischen
Methodenlehre. Görringen: Hogrefe.
The
Journal of Experimental Education, 61 (4), Summer 1993: "Statistical
Significance Testing in Contemporary Practice." mit Beiträgen von Bruce
Thompson, Ronald P. Carver, J. P. Shaver, Carl J. Huberty, et al.
American
Psychological Association, 1984: Publication Manual. Washington D.C.. 4th Edition.
Effektstärke
Artikel
(in
Arbeit)
8.
Das Validitätsproblem: Evaluation der Evaluation
8.1
Verwendungskontext
Tests
sind nicht einfach "valide" oder "invalide", sie dies immer
nur bezogen auf den Prozess der Urteilsbildung und Bewertung, dem sie dienen.
Ein bestimmter Test kann in einem Kontext hoch valide und in einerm anderen völlig
unvalide sein. Ein wichtiger Kontext, der über die Validität eines Tests
mitbestimmt, ist die Frge, ob ein Test a) nur zur Forschungszwecken und zur Evaluation
von Maßnahmen und Methoden herangezogen wird, oder b) zur Bewertung von
Personen und Personengruppen.
a)
Bei der Verwendung von Tests im rein wissenschaftlichen Kontext oder für
die Bewertung von Maßnahmen und Methoden stellt sich die Validitätsfrage.
Tests müssen das messen, was zur Überprüfung einer Theorie oder
einer Maßnahme gemessen werden soll. Man spricht hier von theoretischer
oder konzeptueller Validität. Das heißt, die Messinstrumen ...
(wird fortgesetzt)
8.x
Folgen von Evaluationen mit und ohne Sanktionen
(wird
fotgesetzt)
P.
Sacks (1999): Sanktionen führen nicht zu besseren, sonderen zu schlechteren
Leistungen des Schulsystems ... mehr
