(c) Copyright by G. Lind
Last revision: June 12, 2016
The Moral Competence Test (MCT)
An Introduction by Georg Lind
![]()
Validation and Certification of New Versions
References about the MCT or concerning its theoretical foundation
Update Note (Sept 17, 2015)
The MCT (deutsch: Moralische Kompetenz-Test) has been renamed. It was formerly called Moral Judgment Test (MJT), deutsch: Moralisches Urteil TEst (MUT).
General definition of moral competence:
The ability to resolve problems and conflicts on the basis of moral principles through deliberation and discussion instead of violence, deceit, and force.
Operational definition (MCT):
The ability to rate arguments by the moral quality rather than other criteria like opinion-agreement.
The most up-to-date and authoritative statement on the Moral Competence Test is to be found in:
Lind, G. (2016). How to teach morality. Berlin: Logos.
Lind, G. (2008). The meaning and measurement of moral competence revisited - A dual-aspect model. In: D. Fasko & W. Willis, Eds., Contemporary philosophical and psychological perspectives on moral development and education. Cresskill. NJ: Hampton Press, pp. 185 - 220. download (Password = kohlberg)
Changes:
Correlation with education. Today [2010] we have ample evidence that the correlation between moral competence and amount of education or with graduation level is not always positive and large, but can be small, zero, or even negative if the quality of education is meager, if they are no opportunities for responsibility and guided reflection, and if dogmatic religiosity of the students hinders their learning (see Lind, 2000; Schillinger, 2006; Lupu, 2009). Therefore, we no longer use the correlation with "education" as a validation criterion.
Interpretation of the C-score: see below
The following text has been written about 30 years ago for colleagues who wanted to use the MCT in their research project but could not read the German articles on the MCT. In meantime several articles on the MCT have published in English, which give an up-to-date account of its construction, scoring, and interpretation, and also many articles have appeared on research using the MCT. For this please visit my annotated bibliography: References about the MCT or concerning its theoretical foundation
Table of Contents
1.
Summary
2.
An Overview of the MCT
3. Interpretation of the C-score
4.
The Dual-Aspect-Theory of Moral Behavior and Development
5.
The MCT as an Multivariate, N=1 Experiment
6. Computing
the MCT's C-score
7. Criteria for Evaluating
the MCT: Validity and Utility
8. Evaluating the
validity of the MCT´s C-score
9. Validating
New and Translated Versions of the MCT
10. Evaluating
the Utility of the MCT´s C-score
11. Conclusion
Appendix: Moral Competence Test (Sample. The standard
version can be obtained from the author)
Notes
1.
Summary
The Moral Competence Test (MCT) has been constructed to assess subjects' moral competence, which is the ability to solve problems and conflicts on the basis of universal moral principles through thinking and discussion, but not through violence, deceit, and power (Lind 2015).
Essentially, the MCT assesses moral competence by recording how a subject deals with arguments, especially with arguments that oppose his or her position on a difficult problem. The counter-arguments arguments are the central feature of the MCT. They represent the moral task that the subjects has to cope with. More specifically, in the standard version of the MCT, the subject is confronted with two moral dilemmas and with arguments pro and contra the subject's opinion on solving each of them.
The main score, the C-index, of the MCT measures the degree to which a subject's judgments about pro and con arguments are determined by moral points of view rather than by non-moral considerations like opinion-agreement. It indicates, to use Piaget's terminology, the degree to which moral principles have become "necessary knowledge" (Lourenço & Machado, 1996, p. 154) for the respondent.
Besides this cognitive variable, the MCT lets us also measures subjects' moral ideals or attitudes, i.e., their attitudes toward each stage of moral reasoning as defined by Kohlberg (1958; 1984). In addition, the MCT can be scored for other aspects of a subject's judgment behavior like situational adequacy of moral judgment, extremity of judgment (Heidbrink, 1985), moral closed-mindedness, most preferred stages of reasoning and more (Lind, 1978; Lind & Wakenhut, 1985). In this brief introduction, only the C-index will be discussed, which is the most unique. It is in use since 1976, when the test was created.(2) For a discussion of other measures, see Heidbrink (1985), Lind (1978), and Lind and Wakenhut (1985).
The MCT is an experimental test of moral competence. Its construction is based on an elaborate and well-researched theory of moral behavior and development (Lind, 1982). Its theoretical validity has been evaluated on the basis of very rigorous criteria, which are not available in classical and modern psychometric theory (see Lind 2008).
This means, the MCT is NOT a psychometric test in the sense of classical test theory (Gulliksen 1950) or of Item-Response-Theory (Wilson 2005). These theories do not allow us to measure structure of behavior. The structure of behavior is a very important characteristic of personality and an object of measurement in its own right, and must not be mistaken as "measurement error," as these theories do. They falsely believe that essentially an isolated responses of a person represents fully the trait to be measured, and that this response lacks only "reliability" or "precision", and, therefore, the measurement has to be repeated with responses to identical, or at least very similar, test-items to minimize error variance. If the structure of these responses deviates from the alleged homogeneity and linearity, these deviations are nor recognized as manifestations of individual structure but are believed to be measurement error. Consequently, rather than admitting the existence of different structures, these test-makers eliminate all items from the test which seem to produce these deviations from their conviction ("item selection"). Thus the test becomes more "reliable" but often at the expense of construct validity.
The MCT has not undergone such item-selection. Its items have been solely constructed on the basis of Kohlberg's types of moral orientations, and core postulated of the Dual-Aspect Theory of moral behavior: a) preference hierarchy, b) affective-cognitive parallelism, c) quasi-simplex structure of inter-type-correlations, and d) unfakable (cannot be simulated upward) (see below). The items have been submitted to semantic analysis by experts of moral behavior research, and to case studies in which we tested whether or not the MCT could elicit moral feelings or emotions.Gulliksen, H. (1950). Theory of mental tests. New York Wiley
Lind, G. (1982). Experimental Questionnaires: A new approach to personality research. In: A. Kossakowski & K. Obuchowski, eds., Progress in psychology of personality, pp. 132-144 Amsterdam, NL North-Holland.
Wilson, M. (2005). Constructing measures. An item response modeling approach. Mawah, NJ Erlbaum Associates Publishers.
2. An overview of
the MCT
The standard version of the MCT contains two stories. Each deals with a person who is caught in a behavioral dilemma: whatever he or she decides to do, it will conflict with some rules of conduct. So the 'quality' of the decision is important and not the decision itself. The goodness or badness of the decision depends on the reasons behind it. For many people, it makes a big difference whether somebody behaves well because she or he feels in the mood to do so, or expects to get a reward, or s/he was compelled to do so by outer forces, or because s/he wanted to comply with his or her moral conscience.
Subjects are asked to judge arguments for their acceptability. These arguments present different levels of moral reasoning, six supporting the decision that the protagonist in the story made, and six arguing against his or her decision. So for each dilemma, the respondent is to judge twelve arguments. In the standard version there are then 24 arguments to be rated.
Before judging the acceptability of the arguments presented in the MCT, the subject is asked to rate the rightness or wrongness of the protagonist's decision on a scale from "completely wrong" to "completely right" (see the appendix A). This rating plays no role in scoring a person's moral competence, though it provides important information for designing a valid measure of moral competence.
The scoring of the MCT takes into account the whole pattern of a subject's responses to the test rather than at single acts isolated from one another. We can tell the meaning of a single judgment by a respondent only when we also look at other judgments of that person as well. For examples, if someone judges moral conscience as a highly acceptable reason to commit mercy killing, we cannot be sure whether this judgment reflects a subject's high regard for moral conscience or his or her commitment in favor of mercy killing. In other words, our inferences from single judgments by a person's morality are mostly ambiguous. Only when we consider a person's judgment behavior comprehensively, we can make more unambiguous inferences on a person's morality. How this is achieved with the scoring algorithm is explained below. It should be noted here that the scoring of the MCT contrasts sharply with classical test construction. The latter approach presupposes that a person's judgments can be seen as pure repetitions of one another, masked only by some intervening random processes, which can be averaged out by multiple measurements.
Secondly, The MCT embodies a moral task and not merely a moral attitude or value. If, as we belief, morality has some strong cognitive or competence aspects, we should be able to define a task that can be used to test this competence (Lourenço & Machado, 1996). Many different tasks might come to mind testing moral competencies but only a few are feasible and/or valid. Some tasks may seem suited but are unethical to be used in measurement, like many tests of moral temptation. For example, we must not seduce subjects to steal in order to test their resistance to temptation. Other tasks may seem feasible but lack validity, like the task to help a person in distress. Helping may be motivated by a sense of moral obligation but is not necessarily so. Some helping behavior is, but others may be motivated by a person's desire to dominate another person, by social pressure, by hope for high returns and so on.
An adequate task for testing moral competence is, as experimental research (e.g., Keasey, 1974; Kohlberg, 1958; Walker, 1983; 1986) and moral philosophy (Habermas, 1985; 1990) suggest, to confront a person with counter-arguments. While subjects' reactions to arguments that favor their own opinion indicates the preferred level of moral reasoning for resolving the dilemma, their reactions to counter-arguments tell us something about their ability to use a particular moral level consistently when judging other people's behavior.
The scoring of the MCT follows this notion. A test-taker gets a high competence score only if his or her judgment of pro and contra arguments shows some moral consistency. If a subject lets his or her opinions on the "right" solution of the dilemma determine their ratings of counter-arguments (regardless of their moral quality), the subject will get a low moral competence score on the MCT.
Note, first, that not all kinds of judgment consistency indicate moral competence. Only consistency of a person's judgment in regard to moral concerns qualifies for this, not consistency in regard to other concerns (e.g., to shelter to one's opinion on a certain issue against a critique). So consistency of a person's judgments with his or her opinion on the workers' dilemma is not a valid indicator of moral competence, sometimes rather the opposite, namely moral rigidity.
Second, note that the determination of a person's judgment behavior by moral concerns or principles may or may not be accompanied by a strong commitment for or against a certain solution of the dilemma at stake. Morality and commitment do not exclude one another nor do they necessarily imply each other (Lind, 1978; Lind et al., 1985).
3. Interpretation of the C-score
and other indices
The C-score (or C-index or just C) measures the degree to which s/he lets his or her judgment behavior be determined by moral concerns or principles rather than by other psychological forces like the human tendency to make arguments agree with one's opinion or decision about a certain issue. In other words, the C-index reflects a person's ability to judge arguments according to their moral quality (rather than their opinion agreement or other factors).
C
ranges from 1 to 100. It indicates the percentage of an individual's total
response variation due to a person's concern for the moral quality of given arguments
or behavior. Following a proposal by Cohen (1988), the C is sometimes graded low
(1-9), medium (10-29), high (30-49) and very high
(above 50). For typical mean C of various groups of people, see Lind (2000)
and Lind (1995). How C is computed is explained on page 8.
Today (Nov. 2013) this recommendation, which was written about 30 years ago, is out-dated. We have so much evidence that we can make more meaningful recommendations now:
Most studies report average C-score, not categories anymore. Some also report standard deviations, medians, and inter-quartile ranges. Besides in tables, the important findings should always be graphically depicted, too. The C-score is mostly depicted as the Y-axis, from "0" to "40" or higher, if higher scores occur. Please start the axis always from the "0"-point and to not inflate it to make difference look more impressive. This way your data can be better compared with other studies.
In general, a C-score between 0 and 9 can be interpreted as "very low" or "zero moral competence", between 10 and 29 is the "medium" range in which most (educated) people seem to be. All scores above 30 can be considered as "high moral competence". It seems that the behavior of people with a score higher than 30 is really guided by moral considerations (at least to a large extent): Among these people we hardly find drug consumers, criminals, cheaters, but often find people who help others under stress, engage themselves for democracy, and follow-up their ideals.According to my experience, C-scores and C-score-differences between two groups can only be interpreted if the average C-scores are based on data of at least 15 subjects. A difference of 5 C-points and more can be considered as high, of 10 C-points and more as very high.
Do not interpreted individual scores! The MCT has not been made for individual diagnosis. Individual scores are too unstable, and should not be interpreted or even looked at. Feedback of individual scores would also be a violation of the rule that the MCT data must always be anonymous. The MCT is used for evaluating methods and programs, not people.
Note that only because the MCT contains a moral task (see below), moral competence can be scored by the C-index. (Some authors have also used C with other tests. However, without a moral task, such an index is meaningless.)
While the C is the most often used index, other cognitive-structural properties of persons' moral behavior can also be indexed. For example, the MCT can be designed to assess the degree to which a person's moral differentiates according to the type of dilemma (Lind, 1978). This topic has been neglected for a long time but is now being pursued by many researchers (Krebs et al., 1990; Kurtines & Gewirtz, 1995).
As second set of indices, the MCT produces scores for a person's attitudes toward each of the six levels of moral reasoning that Kohlberg identified. An inspection of these attitudes tells us, for example, whether the preferences for the six stages form a hierarchical order as Kohlberg assumed, that is, which stage of moral reasoning a person prefers most and which least, and for which type of dilemma people prefer a reasoning on the highest level and for which dilemmas they belief a lower stage to be most adequate.
4. The dual aspect theory of moral behavior
and development
The simultaneous assessment of two aspects of moral behavior, cognitive and affective aspects, is the most unique feature of the MCT. As Gross (1993) writes, this "offers a significant improvement over the single score interview technique which conflates these two elements" (p. 14).
This feature is rooted in the dual aspect theory of moral behavior and moral development, as outlined by Jean Piaget, Lawrence Kohlberg and, in more detail, by Lind (1985a; 1985b; 1985c; 2000; 1995). For Piaget (1976) "affective and cognitive mechanisms are inseparable, although distinct: the former depends on energy, and the latter depend on structure" (p. 71). Accordingly, Kohlberg meant his stage model of moral development to be a description of both the affective and the cognitive aspect of moral behavior (Kohlberg, 1958).
The dual aspect theory states that for a comprehensive description of moral behavior both affective as well as cognitive properties need to be considered. A full description of a person's moral behavior involves a) the moral ideals and principles that informs it and b) the cognitive capacities that a person has when applying these ideals and principles in his or her decision making processes.
In contrast, other theories state that affect and cognition represent separate components of the human mind, separated also from moral behavior. They state that there is an affective domain of moral behavior and a cognitive domain, which can be dealt with separately. These theories imply that there are purely affective, cognitive and behavioral responses that can also be assessed separately, for example by using different tests for both components, eliciting the respective type of behavior. "However," Higgins (1995) notes, "there are cognitive aspects to all [. . .] components, and Kohlberg's idea of a stage as a structured whole or a world view, cuts across [. . .] componential models" (p. 53).
There is no necessary connection between the cognitive and affective dimensions of moral reasoning. Although many individuals prefer higher stage moral arguments, only those with more cognitive structures exhibit consistency or reversibility, i.e., the capacity to recognize the moral merit of opposing viewpoints. Invariably, most subjects prefer sophisticated moral arguments when assessing factors favorable to their own position, an outcome stemming from successful socialization to the language of democracy: civic responsibility, civil rights and justice. It is only when asked to evaluate a position contrary to one's own that the importance of cognitive structures emerges. One may prefer universal norms of justice (a high affective score) but be unable to use them consistently, particularly when evaluating the moral position of an adversary (a low competence score). Or, one may exhibit a preference for parochial moral norms (a low affective score) but use them consistently to judge competing moral positions (a high cognitive score).
5.
The MCT as an multivariate N=1 experiment
The MCT rests on modern, cognitive-structural approaches to psychological measurement (see, amongst others: Anderson, 1991; Broughton, 1978; Brunswik, 1955; Burisch, 1984; Cronbach & Meehl, 1955; Kohlberg, 1984; Lind, 1995; Loevinger, 1957; Lourenço & Machado, 1996; Mischel & Shoda, 1995; Pittel & Mendelsohn, 1966; Travers, 1951).
The basic approach we started out with coincides with Kohlberg's: "In order to arrive at the underlying structure of a response, one must construct a test, [. . .] so that the questions and the responses to them allow for an unambiguous inference to be drawn as to underlying structure. [. . .] The test constructor must postulate structure from the start, as opposed to inductively finding structure in content after the test is made. [. . .] If a test is to yield stage structure, a concept of that structure must be built into the initial act of observation, test construction, and scoring" (1984, p. 401-402).
We felt that the best ways of fulfilling this postulate was to design the MCT as a multivariate N = 1 experiment because that way we can make sure that all relevant aspects of a moral task are present in the test and that these aspects are uncorrelated and thus can be clearly identified. As modern psychology reveals, individuals do not only differ in regard to certain moral preferences, attitudes or values but are structurally different. Therefore, we must base the measurement of psychological properties (such as moral competence), on the assessment of individual pattern of behavior rather than on the behavioral pattern of a sample of persons (as is usually done). Otherwise we would commit an ecological fallacy, that is, we would falsely hypothesize that the structure of behavioral data in a sample if individuals is identical with that of each individual. Such a hypothesis, however, is hardly tenable (see Mischel & Shoda, 1995).
Because the function of this experiment is not to test the effects of some treatment but to describe the nature and development of behavioral properties, we call it an ideographic experiment. This special function entails some special kinds of experimental analysis. The independent variables (or factors) are varied in order to study the functioning of the individual's mind but not to assess 'general' effects of these factors. Modern cognitive-structural research found that these effects differ much from one person to another depending on their level of development (Lind, 1978; 1985a; 1985c; 2000; Krebs et al., 1990).
The dependent variable is represented by the subject's judgment behavior, that is, by his or her rating of the arguments on a scale from -4 to +4. (Note that this scale may also range from -2 to +2 for subjects that have difficulties with such a fine-graded scale.)
The moral factor determining subjects' judgment behavior is represented by the moral quality of the arguments. With the MCT, moral quality was defined using Kohlberg's six stages of moral reasoning (Kohlberg, 1958; 1984).
The task factor, opinion agreement or disagreement, is represented by the implication of the argument pro or contra the subject's opinion about the decision of the story's protagonist. The pro-arguments indicate which ideal level of moral discourse the subject prefers; the contra arguments indicate how much the subject let this moral ideal determine his or her judgment of arguments in the presence of other powerful psychological forces.
Finally, the different dilemmas contained in the MCT represent different moral demand structures. In the standard version these differences are small yet noticeable. While the mercy-killing dilemma (taken from Kohlberg's Moral Judgment Interview) is to pull the highest level of moral reasoning on Kohlberg's stage six, the worker's dilemma (adapted from the novel "Stellenweise Glatteis" by Max von der Grün) is thought to pull more Stage 5 reasoning (Lind, 1985a).
In sum, the MCT is designed as a multivariate experiment, with a 6 x 2 x 2 dependent (or multivariate) design, whereby the three design-factors are orthogonal or non-correlated. Its main index, the C-score, is computed by a MANOVA-like method, namely by partitioning sum of squares.
Because of its rationale and its design, the MCT must be viewed as a behavioral experiment rather than a classical psychometric test (Lumsden, 1976). Hence, response consistency and inconsistency indicate properties of a person's moral-cognitive structure, rather than properties of the instrument like "measurement error" or "unreliability" (see Lind, 2008).
In the validation process two type of validity have been of central concern: a) theoretical validity (that is, the degree to which the test actually measures what the theory supposes), and b) communicative validity (that is, the degree to which the subjects understand the test in the same way as the test constructor). To optimize theoretical validity, the construction of the MCT has been based on a) an expensive review of literature and interview material from studies using Kohlberg's Moral Judgment Interview (Colby et al., 1987a; 1987b), and b) several rounds of items writing and expert ratings(3). To secure communicative validity (and also cross-cultural validity of new-language versions), the MCT was submitted to several empirical tests: ac) tests of small groups of subjects, who were speaking aloud while filling out the MCT, and d) several rigorous empirical validation checks as described in the section below.
Note that the MCT was not submitted to traditional "item analysis." That is, no items were selected to increase the correlation of the C-index with empirical criteria like age, political attitudes, or higher education. This fact guarantees that the MCT is not biased in favor or against certain predictions like stability of rank orders among people, age-correlation, or invariant sequence. Most important, the items were not screened either to maximize stability of scores ("reliability") at the expense of the test's sensitivity for education-induced change, or to maximize sensitivity for change at the expense of theoretical validity.
6. Computing the
MCT's C-score
The C-score is computed analogously to multivariate analysis of variance (MANOVA). It can be computed 'by hand' using a pocket calculator. For larger data sets, though, the use of a computer is strongly recommended. In most cases some programming is required because most commercial packages do not provide ready methods for analyzing data individually. However, most packages (like SAS, SPSS, STATISTICA) have a programming language module included that lets you quickly write a program that calculates scores for individual response pattern. The coding scheme for the standard version and a sample program for STATISTICA, version 4.x and 5.x can be requested from the author. A scoring service is also available.
For calculation by hand, a sample calculations are given here: Example for C-score = 0, 15, 100.
To assign the MCT-items to the six stages, the coding scheme is needed, which can be requested from the author.
If you do the calculation of C by hand, this is a good way to do it: First, calculate the Mean Sum of Square (SSM). Add up all raw data for the arguments (24 items; "x" means that all raw data x's are to be added up); then square the sum and divide the sum by the number of items which constitute the mean (here the correct numerical are 24, the number of items of the standard version of the MCT). The result is the Mean Sum of Squares, which is roughly equivalent to the arithmetic mean.
Second, calculate the (adjusted) Total Deviation Sum of Squares (SSDev): Square all raw data x². This is called the unadjusted total sum of squares. Then add up all x² and subtract from this the Means Sum of Squares. This is the SSDev.
Third, calculate the (adjusted) Stage Sum of Squares (SSStage): Add up all four items that belong to a particular stage and square the sum. For example, for stage 1, the squared sum is:
(x1,worker,pro + x1,worker,con + x1,doctor, pro + x1,doctor,con)².
Repeat this for all six stages. Then add up these six squared sums and divide the result by four (the number of repeated measurement for each stage), which gives you the (unadjusted) stage sum of squares. After subtracting the Mean Sum of Squares from this number, you have the (adjusted) Stage Sum of Squares. [Note that before this, you need to sort the items according to the stages that they represent. The stage coding can be requested from the author.]
Now you have all information needed to calculate the C-index: first, divide the Stage Sum of Squares by the Total Deviation Sum of Squares: SS Stage / SS Dev. This is the coefficient of determination r2. Multiply this number by 100, to get C.
There are several ways to check whether your calculation is correct, and they should all be considered to make sure that the calculations are technically correct:
. Recalculate everything once more. This should always be done if you do the calculation by hand or table calculator.
. Make plausibility-checks: The SSStage must never be bigger than the SSDev. The SSMean must never be bigger than the unadjusted SSTotal.
. If you make a program to do the calculation for you on the computer: run trials with numbers that you can easily check by hand. Try several patterns of numbers like all "1," which should give you a "0" for all adjusted numbers, e.g., SSStage and SSDev, or all "1" for stages 1 to 3 and all "0" for stages 4 to 6. This should give you a high value for SSStage.
To find and eliminate "bugs" in your program, the best way is to calculate the score again. If the results keep changing, review your calculation technique. Use the scheme below to calculate the C-index.
Errors may also occur when keying in the data. So double-check both. I have found that some spreadsheet programs make errors in adding simple numbers. My WordPerfect word processor does this sometimes. For example, when I enter a negative number, the minus sign is sometimes changed into a dash sign and then ignored by the program.
Some statistical packages also have a hard time doing what the programmers tell them to do. When you are not sure, do both things: a) compare the computer's calculations of a simple example with your hand-done calculations; try different number patterns because only then you can be fairly sure that the program works correctly; b) check the empirical findings using the criteria explained above in the section "Validating new and translated versions of the MCT." Both methods helped me to identify technical data errors.
7. Criteria for evaluating the MCT:
Validity and Utility
The Moral Competence Test is to serve two purposes: it should allow us to test modern theories of moral development and education, and it should allow us to evaluate educational methods as to their power to enhance moral competencies. For these two purposes, we sought to make the MCT as theoretically valid and educationally useful as possible.
In psychology as in most other sciences, tests and measuring devices are made to provide data. With these data we want to test the empirical truth of theories (or of hypotheses derived from those theories), or to evaluate the effects of certain methods or interventions, or both at the same time. If we use the measuring device to test theories, this device needs to be theoretically valid, that is, it must really measure what it is supposed to measure. Otherwise, the data produced by this device are irrelevant for the theory to be evaluated, and thus useless (Cronbach & Meehl, 1955; Popper, 1979). If we use a measuring device to evaluate methods of education or psychotherapy, a measuring device must be educationally useful, that is, it must measure exactly the aspects of human behavior and development that we wish to educate or cure.
Currently, in the field of moral psychology and moral education, there is a particular need for a theoretically valid measure of moral competence. The idea that moral behavior and development has a cognitive aspect, is rather new and still very controversial. Eminent scholars like Jean Piaget and Lawrence Kohlberg maintain that morality has a strong cognitive component. Yet, does such a component or aspect really exist, that is, can it be measured and shown to be relevant for human behavior? Does it develop in the way that we think it does? What causes its development and its erosion? To answer these questions we need a test that really measures the competence aspect of moral behavior rather than other aspects like moral attitudes and values.
The educational utility of a test of moral competence requires a test not only to be theoretically valid. To evaluate educational or therapeutic interventions, a test needs also to be transparent and credible for everybody involved in the education process: teachers, students, school administrators, and taxpayer. A test's transparency and credibility are severely restricted, a) if the test's design provides no means for choosing between competing interpretations of the test scores, b) if different aspects of morality are confounded in one score, and c) if the scoring is based on subjective ratings rather than objective algorithms. In other words, a test of moral behavior and development should be designed to facilitate unambiguous and uncompounded scores, and the scoring procedure should be traceable.
8.
Evaluating the validity of the MCT's C-index
The original (German) version of the MCT was validated in respect to several analytical and empirical criteria. The analytical criteria of validation included a strictly theory-based test-construction (in contrast to a test construction that seeks to maximize certain statistical coefficients), and an extensive expert rating of the test items. Half a dozen experts of Kohlberg's stage model of moral development commented on the theoretical adequacy of the arguments in the MCT (see above).
The empirical criteria
included four predictions derived from cognitive-developmental theory that seemed
to be supported by Kohlbergian research (Kohlberg, 1958; Rest, 1979; Walker, 1986;
an empirical example will be given in the section 9 below):
1. The order of preferences: In a truly
moral dilemma, subjects should prefer the stages of moral reasoning in the order
of their number, with highest preference for stage six-reasoning and lowest preference
for stage-one-reasoning. To my knowledge, all MCT-studies have found such
a preference order.
2.
Quasi-simplex structure: The correlation between the preferences of neighboring
stages (like four and five) should be higher than the correlation between more
distant stages (like four and six). On other words, in the correlation matrix
of all stages, the coefficients should decrease monotonously from the diagonal
toward the corners of the matrix. This can be tested in several ways. For example,
it can be tested through computer programs that sort the correlation coefficients
to optimize quasi-simplex structure (like the TAM program of the KOSTAS package
by W. Nagl et al., 1986). If the program finds no better structure of coefficients
than the one found, the finding can be regarded as an optimal fit though minor
deviations may have occurred. Most, if not all, MCT-studies have produced
such an optimal quasi-simplex-structure much clearer than the original study by
Kohlberg (1958).
3. Cognitive-affective
parallelism: If subjects present their own moral attitudes (rather than faked
or socially desired attitudes), these scores should be systematically correlated
with their moral competence score, with high negative correlations between the
C-score on the one hand, and attitude scores for stages 1 and 2, on the
other, and moderate correlations between C and attitudes to stages 3 and
4, and substantial positive correlations between C and attitudes to stages
5 and 6 (Lind, 1985a). Most, if not all, MCT-studies found a marked pattern
of correlations between these two aspects of moral behavior, corroborating
Piaget´s parallelism theorem.
4.
Equivalence of pro and con arguments: The arguments in favor of a certain
solution of a moral dilemma should be equivalent to the arguments of against it,
that is, subjects agreeing with the given solution of a dilemma should be confronted
with arguments of approximately the same quality as subjects disagreeing with
this solution. In his dissertation, Lind (not cited) found this hypothesis clearly
supported.
5. A difficult
moral task, which cannot be simulated. The claim that the MCT represents a moral task and
that its C-index is a measure of moral competencies (rather than
of moral attitude), has been corroborated in two crucial experiments. In
these experiment, subjects were instructed to simulate a score that is
above their own (see Emler et al., 1983). While subjects could simulate higher
scores with other tests of moral development, subjects were not able to simulate
a higher C-score when responding to the MCT (Lind, 2000; Wasel,
1994). Obviously, the other instruments measured moral attitudes rather
than moral competence.
The effect of simulation was tested by letting the subjects fill out a test twice, one time with the regular instruction to fill out the questionnaire or test. At second time, the subjects were instructed to fill out the test again, but this time to fill it out as if one were another person. Specifically, subjects were first divided into two groups on the basis of their political orientation. Because political orientation is consistently correlated with scores of moral development tests, the two groups also differed: those who described themselves as left wingers (liberals) had higher scores than right wingers (conservatives). So left wingers were instructed to fill out the test as if they were right wingers, and right wingers were instructed to fill it out as if they were left wingers. It was hypothesized that, while leftists should have no difficulty simulating the (lower) scores, the latter group should not be able to simulate the (higher) scores of their counterparts, if the test really measures competence. If not, both groups should be equally able to simulate the test scores according to the instruction.
In a first series of experiments, the Defining Issues Test (Rest, 1979) and the Survey of Ethical Attitudes by Hogan were benchmarked. The results of these experiments were that the scores could be simulated in either direction, that is, that subjects could fake their scores upward (Emler et al., 1983; Markoulis, 1989; Barnett, Evens, & Rest, 1995; see also Lind, 1995), and that, therefore, these instruments seem to assess moral attitude rather than moral competence.
Using the same setting and the same type of subjects as Emler et al. (1983), Lind (1995) found that subjects who were asked to fill out the MCT as a "leftist" would, were not able to fake their C-scores upward. Wasel (1994) showed that the instruction to simulate the moral reasoning of colleagues who had a higher C than oneself, did not increase the subject's score. Yet in both experiments, subjects with high C-index could be instructed to simulate lower scores than their own.
The competence nature of C-index is also supported by the fact that, in longitudinal studies, upward changes were always gradual rather than abrupt (Lind, 2000; 1995). Gradual changes are typical for the acquisition of abilities but not for the change of attitudes, which may sometimes be very abrupt and dramatic when people change their social context.
Finally, moral competence
only erodes slowly. The forgetting curve of subjects' C-score is negatively
accelerated, that is, the longer subjects do not practice their moral abilities,
the faster they lose them (Lind, 2000; 1995).
So the C-index of the MCT meets all four criteria of a competence-index (moral task, non-fakability, gradual learning curve and smooth forgetting curve). Moreover, it is calculated so that it is logically independent from a person's moral attitudes (Lind, 2000; 1995; Wasel, 1994). It can be high or low regardless of a person's like or dislike for moral principles. Therefore, we call C a pure index of moral competence, in contrast to other, which are compound scores of moral cognition and moral attitudes (for a discussion, see Lind & Wakenhut, 1983; Lind, 1995). This fact makes the MCT less dependent on irrelevant empirical criteria and on criteria which would bias the test toward some theories.
Note again that the MCT was constructed solely on the basis of theoretical considerations rather than on empirical criteria. Empirical criteria, deduced from theoretical propositions, are used only to check new (or translated) versions of the MCT for theoretical or cultural equivalence with the original version (see below). Hence, it should not be benchmarked against other tests by mere empirical means. Without reference to the theory and research underpinning the MCT, we cannot know whether the MCT lacks validity or the criterion, if the correlation comes out low.
Presently (year 2002), there is empirical evidence from research of more than 200,000 subjects of different culture, age, gender, socioeconomic status and level of education, that the MCT fulfills well these five validity criteria that we have discussed above (Lind, 2000; 1995). See the list of certified translated MCT versions.
9. Validating and certifying new and translated versions of the MCT
Because any inference that we base on data depends heavily on the quality of those data and, therefore, on the validity of the measurement process, careful validation procedures of a measurement instrument are very important. In cross-cultural research they are even more important as we may falsely interpret methodological differences between cultures as substantial ones. Only if the translation of the test has been carefully done (including backward translation) and if the empirical data agree fairly well with those four indicators, one can assume that a newly created version of the MCT is fairly valid and equivalent to the original (German) version, which is a necessary condition for comparing findings across countries. If cultural validity is low or unknown, we have no way to attribute difference in data to any substantial variable.
This theory-based empirical validation procedure requires more time and funding than is typically thought necessary. However, it pays well in terms of more trustworthy, meaningful and comparable data. This procedure provides validity criteria independent from the research for which it will be subsequently used, making circular conclusions and tautologies less likely and findings more credible. A careful cultural validation process, is demonstrated in the cross-cultural studies by Michael Gross, who investigated the relationship between moral development and political involvement in Israel, France, the Netherlands, and the United States (Gross, 1994; 1995a; 1995b).
Studies that omit this validation process because it consumes considerable time and money, usually pay for this omission by producing ambiguous, if not useless data. They do not, as the authors of those studies claim, warrant any substantial interpretation other than that the data are not valid.
The requirement of validity applies not only to the original test but also to new sub-test (dilemmas) and to foreign language versions. In the following we summarize a procedure for securing the validity of new sub-tests and foreign language versions of the MCT, which employs the empirical criteria discussed above and one additional criterion. These four criteria have been found very effective for detecting and curing serious flaws in new or translated versions.
The first step of validating any foreign version of a test, is to translate that version backward into the original language. There are a German and an English version of the MCT that can be used for backward translation and checking the equivalence of the new version. Many flaws can be already detected this way.
The second step in validating new MCT versions involves a small empirical validation ... more
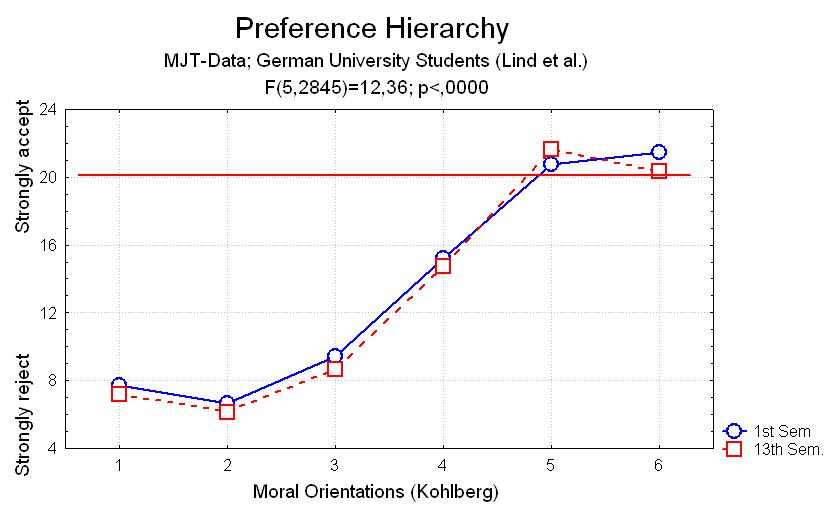
Preference hierarchy: The preferences for the six Kohlbergian stages of moral reasoning should be ordered as theoretically predicted, with stage 6 preferred most, stage 5 second most etc. (see the figure on the left). Some small inversions of stage preferences (especially between stages 1 and 2, as well as between stages 5 and 6) may occur, and do not invalidate the new test version. Cross-cultural research supports this hypothesis quite well (Lind, 1986; Gross, 1996).
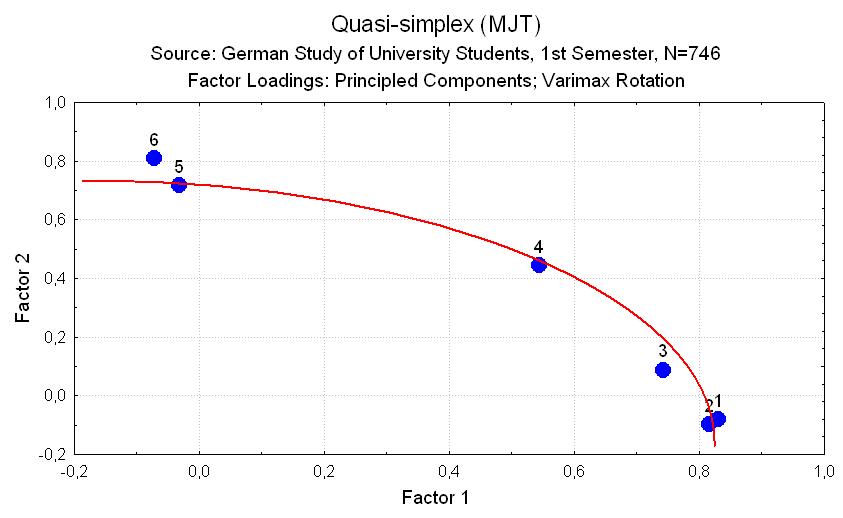
Quasi-simplex structure of stage preference inter-correlations: Neighboring stages (for example, stages 5 and 6) should correlate higher than more distant stages (for example, stages 4 and 6), that is, the correlations should monotonously decrease from the diagonal to the left lower corner of the correlation matrix.
This criterion can be tested in two ways: a) in a main-component factor analysis with varimax-rotation, two factors should be produced and the factor loadings for the preference scores for the six stages should be orderly located on a simplex curve between the two (see graph); b) attempts to bring the matrix of the inter-correlations between the preferences for the six stages into a more simplex-like order should not result in a re-ordering of the six stages.
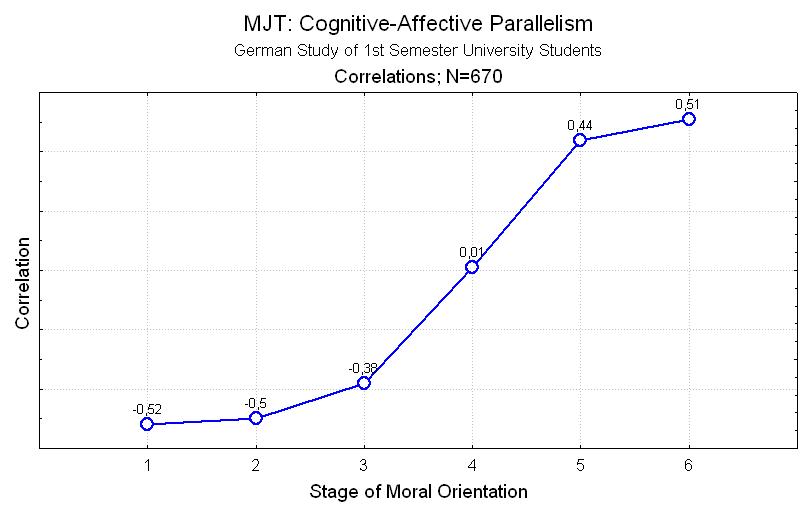
Affective-cognitive parallelism: The stage preferences should correlate in a predicted manner with the MCT's C-index of moral competence, i.e., while the preference for the highest stages should correlate highly positively with the competence score, the preferences for the lowest stages should correlate highly negatively with that score, and the other MCT preference indices should show correlations in between these extremes.
Correlation with education. [Outdated text:] Given the above described sample, C should correlate highly positive ( r > 0.40) with amount and quality of education of the subjects. Correlation of C with Ss' age should be small or close to zero when level of education is hold constant. In the first validation study of the Brazilian MCT, the correlation between C-score and level of education was r = 0.40.
Today [2010] we have ample evidence that the correlation between moral competence and amount of education or with graduation level can be small, zero, or even negative if the quality of education is meager, if they are no opportunities for responsibility-taking and guided reflection, and if dogmatic religiosity of the students hinders their learning (see Lind, 2000; Schillinger, 2006; Lupu, 2009). Therefore, we no longer use the correlation with "education" as a validation criterion.
No upward simulation of the C-index. As shown above, the MCT has been constructed to assess the cognitive, or competence aspect of judgment behavior rather than merely moral attitudes. When submitted to experimental setting like that used by Emler et al. (1983), the C-score of a newly constructed MCT version should show no upward change (see Lind, 2002). This criterion is optional.
Note that these findings do not only support the cross-cultural validity of the Brazilian version of the MCT by Patricia U. Bataglia, but also the universal validity of the cognitive-developmental theory of moral behavior and development.
See the list of certified translated MCT versions.
10.
The utility of the MCT's C-index for evaluation studies
The utility for evaluation studies of the MCT is manifold:
a) The MCT it is theoretically valid; therefore the C-score can be easily interpreted in terms of the theory on which it is based;
b) the MCT's C-score cannot be faked upward, hence positive effects of an educational program can be attributed unambiguously to the quality of the program rather than to social desirability or so-called Hawthorn effects;
c) the MCT has shown to be sensitive to educational effects which could not be detected with other tests (Lind, 2000);
d) because the MCT is short, it can be administered in studies in which several hundreds of subjects must be studies and resources (time, money) are scarce.
11.
Conclusion
The MCT
can be used to test predictions derived from theories of moral development
because, on the basis of almost twenty years of research summarized in a series
of publications (e.g., Lind, 1985 a/b/c; 2000; 1995). It has shown to be highly
valid. Moreover, because the MCT is short and easy to score by computer,
it can be used to evaluate educational programs and other conditions of moral
development that involve large samples of persons. The MCT has shown
to be sensitive to educational treatments but not to instructions to fake scores
high.
Appendix
A
complete copy of the MCT in German, English and other certified versions
can be ordered for free from the author. See address.
| Due to some seemingly unfounded dismissals, some factory workers suspect the managers of eavesdropping on their employees through an intercom and using this information against them. The managers officially and emphatically deny this accusation. The union declares that it will only take steps against the company when proof has been found that confirms these suspicions. Two workers then break into the administrative offices and take tape transcripts that prove the allegation of eavesdropping. | Do you disagree or agree with the workers' behavior? | ||||
| |||||
| Do you accept or reject the following arguments in favor of the two workers' behavior? Suppose someone argued they were right . . . (5). 1. because they didn't cause much damage to the company. |
| ||||
| 2. because due to the company's disregard for the law, the means used by the two workers were permissible to restore law and order. | |||||
| 3. because most of the workers would approve of their deed and many of them would be happy about it. | |||||
| 4. because trust between people and individual dignity count more than the firm's best | |||||
| 5. because since the company had committed an injustice first, the two workers were justified in breaking into the offices | |||||
| 6. because the two workers saw no legal means of revealing the company's misuse of confidence, and therefore chose what they considered the lesser evil. | |||||
Note: This is not a complete version of the standard MCT. Six more
arguments are given speaking against the workers. In addition, the mercy killing
dilemma is presented with six arguments in favor and six against the proposed
solution.
To obtain
a copy of the MCT for research and evaluation studies, please contact the author.
Indicate the desired language version.
NOTES
1. Author's address: Prof. Dr. Georg Lind, Konstanz. Personal web-page. E-mail: georg.lind[ät]uni-konstranz.de
2. In former publications, I also used other names for the C-index: "DetStufe" (German) and "DetStage" (English), which is an abbreviation for the degree of determination of the individual's judgment behavior by the experimental factor "stage of reasoning."
3. For their expert ratings to, and valuable critique of, the original MCT and subsequent revisions and alternate version, I wish to thank Tino Bargel, Ralf Briechle, Helen Haste, Thomas Krämer-Badoni, Horst Heidbrink, Cristina Moreno, Gertrud Nunner-Winkler, Gerhard Portele, Ernst-Heinrich Schiebe, José Trechera, Roland Wakenhut, Thomas Wren.
4. The attitude scores are usually computed by dividing the summated rating by 4 and subtracting -4 in order to get numbers in the range of the original response scale of the items: from -4 to +4.
5. The text of the standard MCT version has been changed in December 2001 from "How acceptable do you find ..." to "Do you accept or reject..." in response to well-founded by Michael Hauan, University of Missouri.